列表键的底层就是一个链表
链表节点
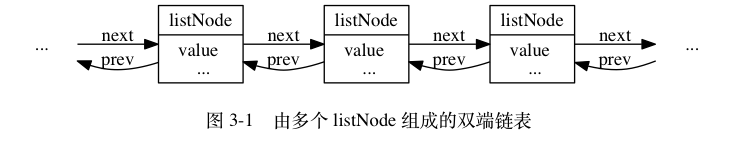
每个链表节点使用一个 adlist.h/listNode 结构来表示:1
2
3
4
5
6
7
8
9
10
11
12typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。