不想分几章了,所以很长很长👿
docker 容器的状态机
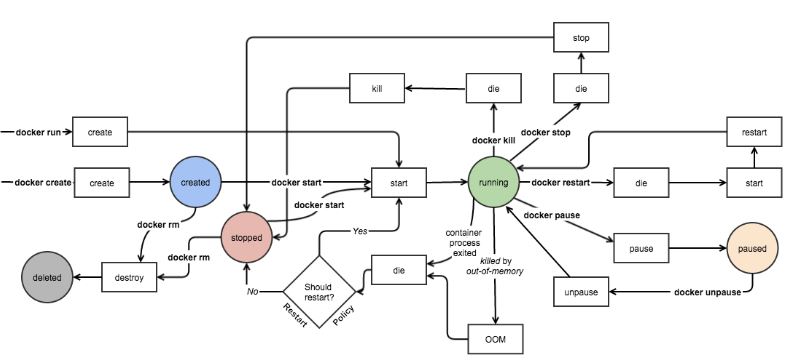
一个容器在某个时刻可能处于以下几种状态之一:
- created:已经被创建 (使用 docker ps -a 命令可以列出)但是还没有被启动 (使用 docker ps 命令还无法列出)
- running:运行中
- paused:容器的进程被暂停了
- restarting:容器的进程正在重启过程中
- exited:上图中的 stopped 状态,表示容器之前运行过但是现在处于停止状态(要区别于 created 状态,它是指一个新创出的尚未运行过的容器)。可以通过 start 命令使其重新进入 running 状态
- destroyed:容器被删除了,再也不存在了
Docker 命令概述
我们可以把Docker 的命令大概地分类如下:
1 | 镜像操作: |
docker save和docker export的区别
- docker save保存的是镜像(image),docker export保存的是容器(container);
- docker load用来载入镜像包,docker import用来载入容器包,但两者都会恢复为镜像;
- docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
Doker 平台的基本构成
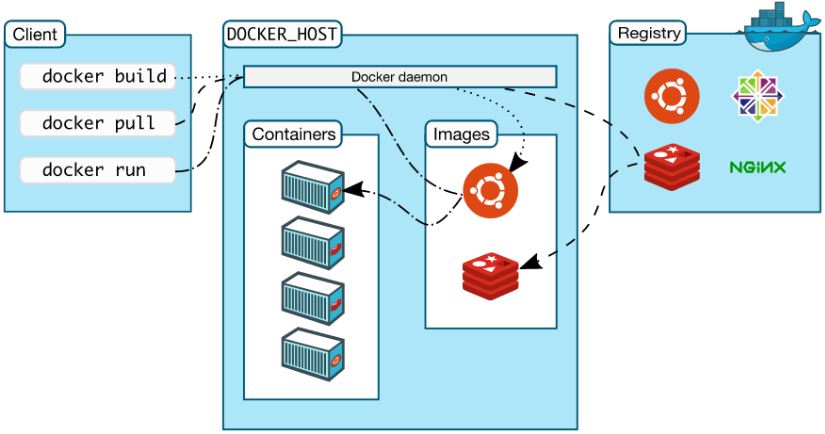
Docker 平台基本上由三部分组成:
- 客户端:用户使用 Docker 提供的工具(CLI 以及 API 等)来构建,上传镜像并发布命令来创建和启动容器
- Docker 主机:从 Docker registry 上下载镜像并启动容器
- Docker registry:Docker 镜像仓库,用于保存镜像,并提供镜像上传和下载
Host OS VS Guest OS VS Base image
比如,一台主机安装的是 Centos 操作系统,现在在上面跑一个 Ubuntu 容器。此时,Host OS 是 Centos,Guest OS 是 Ubuntu。Guest OS 也被成为容器的 Base Image。
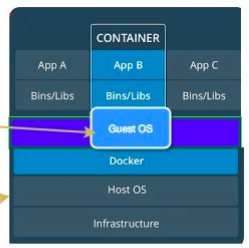
一些说明:
- 关于 linux 内核和版本:所有 Linux 发行版都采用相同的 Linux 内核(kernel),然后所有发行版对内核都有轻微改动。这些改动都会上传回 linux 社区,并被合并。
- 关于Linux 容器环境:因为所有Linux发行版都包含同一个linux 内核(有轻微修改),以及不同的自己的软件,因此,会很容易地将某个 userland 软件安装在linux 内核上,来模拟不同的发行版环境。比如说,在 Ubuntu 上运行 Centos 容器,这意味着从 Centos 获取 userland 软件,运行在 Ubuntu 内核上。因此,这就像在同一个操作系统(linux 内核)上运行不同的 userland 软件(发行版的)。这就是为什么Docker 不支持在 Linux 主机上运行 FreeBSD 或者windows 容器。
可见,容器的 base image 并不真的是 base OS。Base image 会远远比 base OS 更轻量。它只安装发行版特殊的部分(userland 软件)。
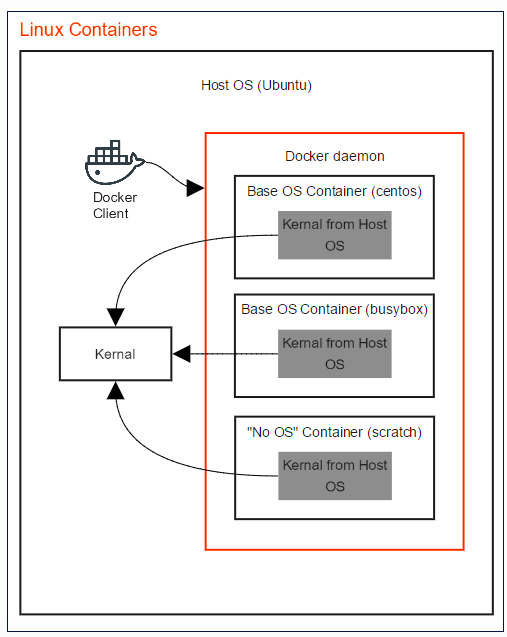
那为什么还需要 base image 呢?这是因为,docker 容器文件系统与 host OS 是隔离的。容器镜像中的应用软件无法看到主机文件系统,除非将主机文件系统挂载为容器的卷。因此,可以想像一下,你容器中的应用依赖于各种操作系统库,因此我们不得不将这些库打包到镜像之中。另外,base image 会让我们使用到各个发行版的包管理系统,比如 yum 和 apt-get。而且,各个linux 发行版的 base image 也不是普通的发行版,而是一个简化了的版本。而且,base image 并不带有 linux 内核,因为容器会使用主机的内核。
因此,需要注重理解 image 和 OS 这两个概念。之所以成为 base image,而不是 base OS,是因为 base image 中并不包括完整的 OS。而这一点,是容器与虚拟机之前的本质区别之一。那就是,容器并没有虚拟化,而是共享主机上的linux 内核。
Docker 镜像分层,COW 和 镜像大小(size)
镜像分层和容器层
一个 Docker 镜像是基于基础镜像的多层叠加,最终构成和容器的 rootfs (根文件系统)。当 Docker 创建一个容器时,它会在基础镜像的容器层之上添加一层新的薄薄的可写容器层。接下来,所有对容器的变化,比如写新的文件,修改已有文件和删除文件,都只会作用在这个容器层之中。因此,通过不拷贝完整的 rootfs,Docker 减少了容器所占用的空间,以及减少了容器启动所需时间。
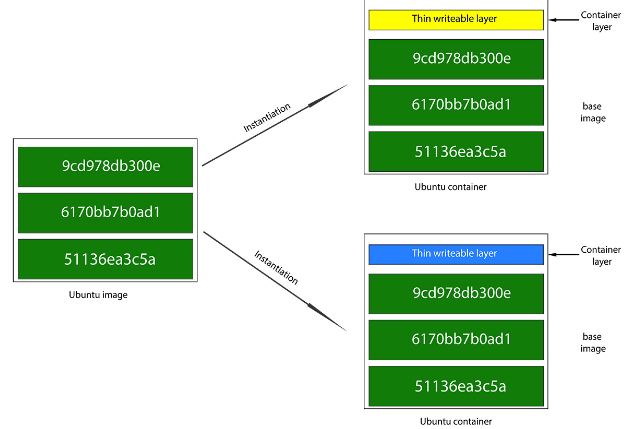
COW 和镜像大小
COW,copy-on-write 技术,一方面带来了容器启动的快捷,另一方也造成了容器镜像大小的增加。每一次 RUN 命令都会在镜像上增加一层,每一层都会占用磁盘空间。举个例子,在 Ubuntu 14.04 基础镜像中运行 RUN apt-get upgrade 会在保留基础层的同时再创建一个新层来放所有新的文件,而不是修改老的文件,因此,新的镜像大小会超过直接在老的文件系统上做更新时的文件大小。因此,为了减少镜像大小起见,所有文件相关的操作,比如删除,释放和移动等,都需要尽可能地放在一个 RUN 指令中进行。
使用容器需要避免的一些做法
这篇文章 10 things to avoid in docker containers 列举了一些在使用容器时需要避免的做法,包括:
- 不要在容器中保存数据(Don’t store data in containers)
- 将应用打包到镜像再部署而不是更新到已有容器(Don’t ship your application in two pieces)
- 不要产生过大的镜像 (Don’t create large images)
- 不要使用单层镜像 (Don’t use a single layer image)
- 不要从运行着的容器上产生镜像 (Don’t create images from running containers )
- 不要只是使用 “latest”标签 (Don’t use only the “latest” tag)
- 不要在容器内运行超过一个的进程 (Don’t run more than one process in a single container )
- 不要在容器内保存 credentials,而是要从外面通过环境变量传入 ( Don’t store credentials in the image. Use environment variables)
- 不要使用 root 用户跑容器进程(Don’t run processes as a root user )
- 不要依赖于IP地址,而是要从外面通过环境变量传入 (Don’t rely on IP addresses )
Linux namespace 的概念
Linux 内核从版本 2.4.19 开始陆续引入了 namespace 的概念。其目的是将某个特定的全局系统资源(global system resource)通过抽象方法使得namespace 中的进程看起来拥有它们自己的隔离的全局系统资源实例(The purpose of each namespace is to wrap a particular global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. )。Linux 内核中实现了六种 namespace,按照引入的先后顺序,列表如下:
| namespace | 引入的相关内核版本 | 被隔离的全局系统资源 | 在容器语境下的隔离效果 |
|---|---|---|---|
| Mount namespaces | Linux 2.4.19 | 文件系统挂接点 | 每个容器能看到不同的文件系统层次结构 |
| UTS namespaces | Linux 2.6.19 | nodename 和 domainname | 每个容器可以有自己的 hostname 和 domainame |
| IPC namespaces | Linux 2.6.19 | 特定的进程间通信资源,包括System V IPC 和 POSIX message queues | 每个容器有其自己的 System V IPC 和 POSIX 消息队列文件系统,因此,只有在同一个 IPC namespace 的进程之间才能互相通信 |
| PID namespaces | Linux 2.6.24 | 进程 ID 数字空间 (process ID number space) | 每个 PID namespace 中的进程可以有其独立的 PID; 每个容器可以有其 PID 为 1 的root 进程;也使得容器可以在不同的 host 之间迁移,因为 namespace 中的进程 ID 和 host 无关了。这也使得容器中的每个进程有两个PID:容器中的 PID 和 host 上的 PID。 |
| Network namespaces | 始于Linux 2.6.24 完成于 Linux 2.6.29 | 网络相关的系统资源 | 每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端口号等等。这也使得一个 host 上多个容器内的同一个应用都绑定到各自容器的 80 端口上。 |
| User namespaces | 始于 Linux 2.6.23 完成于 Linux 3.8) | 用户和组 ID 空间 | 在 user namespace 中的进程的用户和组 ID 可以和在 host 上不同; 每个 container 可以有不同的 user 和 group id;一个 host 上的非特权用户可以成为 user namespace 中的特权用户; |
Linux namespace 的概念说简单也简单说复杂也复杂。简单来说,我们只要知道,处于某个 namespace 中的进程,能看到独立的它自己的隔离的某些特定系统资源;复杂来说,可以去看看 Linux 内核中实现 namespace 的原理,网络上也有大量的文档供参考,这里不再赘述。
Docker 容器使用 linux namespace 做运行环境隔离
当 Docker 创建一个容器时,它会创建新的以上六种 namespace 的实例,然后把容器中的所有进程放到这些 namespace 之中,使得Docker 容器中的进程只能看到隔离的系统资源。
Mount Namespace
Mount namespace用来隔离文件系统的挂载点, 使得不同的mount namespace拥有自己独立的挂载点信息,不同的namespace之间不会相互影响,这对于构建用户或者容器自己的文件系统目录非常有用。
当前进程所在mount namespace里的所有挂载信息可以在/proc/[pid]/mounts、/proc/[pid]/mountinfo和/proc/[pid]/mountstats里面找到。
Mount namespaces是第一个被加入Linux的namespace,由于当时没想到还会引入其它的namespace,所以取名为CLONE_NEWNS,而没有叫CLONE_NEWMOUNT。
每个mount namespace都拥有一份自己的挂载点列表,当用clone或者unshare函数创建新的mount namespace时,新创建的namespace将拷贝一份老namespace里的挂载点列表,但从这之后,他们就没有关系了,通过mount和umount增加和删除各自namespace里面的挂载点都不会相互影响。
PID namespace
我们能看到同一个进程,在容器内外的 PID 是不同的:
- 在容器内 PID 是 1,PPID 是 0。
- 在容器外 PID 是 2198, PPID 是 2179 即 docker-containerd-shim 进程.
1 | root@devstack:/home/sammy# ps -ef | grep python |
关于 containerd,containerd-shim 和 container 的关系,文章 中的下图可以说明:
- Docker 引擎管理着镜像,然后移交给 containerd 运行,containerd 再使用 runC 运行容器。
- Containerd 是一个简单的守护进程,它可以使用 runC 管理容器,使用 gRPC 暴露容器的其他功能。它管理容器的开始,停止,暂停和销毁。由于容器运行时是孤立的引擎,引擎最终能够启动和升级而无需重新启动容器。
- runC是一个轻量级的工具,它是用来运行容器的,只用来做这一件事,并且这一件事要做好。runC基本上是一个小命令行工具且它可以不用通过Docker引擎,直接就可以使用容器。
因此,容器中的主应用在 host 上的父进程是 containerd-shim,是它通过工具 runC 来启动这些进程的。
这也能看出来,pid namespace 通过将 host 上 PID 映射为容器内的 PID, 使得容器内的进程看起来有个独立的 PID 空间。
UTS namespace
类似地,容器可以有自己的 hostname 和 domainname:
1 | root@devstack:/home/sammy# hostname |
IPC Namespace
IPC全称 Inter-Process Communication,是Unix/Linux下进程间通信的一种方式,IPC有共享内存、信号量、消息队列等方法。所以,为了隔离,我们也需要把IPC给隔离开来,这样,只有在同一个Namespace下的进程才能相互通信。如果你熟悉IPC的原理的话,你会知道,IPC需要有一个全局的ID,即然是全局的,那么就意味着我们的Namespace需要对这个ID隔离,不能让别的Namespace的进程看到。
user namespace
在 Docker 1.10 版本之前,Docker 是不支持 user namespace。也就是说,默认地,容器内的进程的运行用户就是 host 上的 root 用户,这样的话,当 host 上的文件或者目录作为 volume 被映射到容器以后,容器内的进程其实是有 root 的几乎所有权限去修改这些 host 上的目录的,这会有很大的安全问题。
举例:
- 启动一个容器: docker run -d -v /bin:/host/bin –name web34 training/webapp python app.py
- 此时进程的用户在容器内和外都是root,它在容器内可以对 host 上的 /bin 目录做任意修改
而 Docker 1.10 中引入的 user namespace 就可以让容器有一个 “假”的 root 用户,它在容器内是 root,在容器外是一个非 root 用户。也就是说,user namespace 实现了 host users 和 container users 之间的映射。
启用步骤:
- 修改 /etc/default/docker 文件,添加行 DOCKER_OPTS=”–userns-remap=default”
- 重启 docker 服务,此时 dockerd 进程为 /usr/bin/dockerd –userns-remap=default –raw-logs
- 然后创建一个容器:docker run -d -v /bin:/host/bin –name web35 training/webapp python app.py
- 查看进程在容器内外的用户:
1 | root@devstack:/home/sammy# ps -ef | grep python |
查看文件/etc/subuid 和 /etc/subgid,可以看到 dockermap 用户在host 上的 uid 和 gid 都是 231072:
1 | root@devstack:/home/sammy# cat /etc/subuid |
再看文件/proc/1726/uid_map,它表示了容器内外用户的映射关系,即将host 上的 231072 用户映射为容器内的 0 (即root)用户。
1 | root@devstack:/home/sammy# cat /proc/1726/uid_map |
现在,我们试图在容器内修改 host 上的 /bin 文件夹,就会提示权限不足了:
1 | root@80993d821f7b:/host/bin# touch test2 |
这说明通过使用 user namespace,我们就成功地限制了容器内进程的权限。
network namespace
默认情况下,当 docker 实例被创建出来后,使用 ip netns 命令无法看到容器实例对应的 network namespace。这是因为 ip netns 命令是从 /var/run/netns 文件夹中读取内容的。
步骤:
找到容器的主进程 ID
1
2root@devstack:/home/sammy# docker inspect --format '{{.State.Pid}}' web5
2704创建 /var/run/netns 目录以及符号连接
1
2root@devstack:/home/sammy# mkdir /var/run/netns
root@devstack:/home/sammy# ln -s /proc/2704/ns/net /var/run/netns/web5此时可以使用 ip netns 命令了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15root@devstack:/home/sammy# ip netns
web5
root@devstack:/home/sammy# ip netns exec web5 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
15: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:3/64 scope link
valid_lft forever preferred_lft forever
Linux control groups
概念
Linux Cgroup 可让您为系统中所运行任务(进程)的用户定义组群分配资源 — 比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。您可以监控您配置的 cgroup,拒绝cgroup 访问某些资源,甚至在运行的系统中动态配置您的 cgroup。所以,可以将 controll groups 理解为 controller (system resource) (for) (process)groups,也就是是说它以一组进程为目标进行系统资源分配和控制。
它主要提供了如下功能:
- Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting: 一些审计或一些统计,主要目的是为了计费。
- Control: 挂起进程,恢复执行进程。
使用 cgroup,系统管理员可更具体地控制对系统资源的分配、优先顺序、拒绝、管理和监控。可更好地根据任务和用户分配硬件资源,提高总体效率。
在实践中,系统管理员一般会利用CGroup做下面这些事(有点像为某个虚拟机分配资源似的):
- 隔离一个进程集合(比如:nginx的所有进程),并限制他们所消费的资源,比如绑定CPU的核。
- 为这组进程分配其足够使用的内存
- 为这组进程分配相应的网络带宽和磁盘存储限制
- 限制访问某些设备(通过设置设备的白名单)
Linux 系统中,一切皆文件。Linux 也将 cgroups 实现成了文件系统,方便用户使用。
1 | root@devstack:/home/sammy# mount -t cgroup |
我们看到 /sys/fs/cgroup 目录中有若干个子目录,我们可以认为这些都是受 cgroups 控制的资源以及这些资源的信息。
- blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
默认的话,在 Ubuntu 系统中,你可能看不到 net_cls 和 net_prio 目录,它们需要你手工做 mount:
1 | root@devstack:/sys/fs/cgroup# modprobe cls_cgroup |
实验
通过 cgroups 限制进程的 CPU
写一段最简单的 C 程序:
1 | int main(void) |
编译,运行,发现它占用的 CPU 几乎到了 100%:
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
接下来我们做如下操作:
1 | root@devstack:/home/sammy/c# mkdir /sys/fs/cgroup/cpu/hello |
然后再来看看这个进程的 CPU 占用情况:
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
它占用的 CPU 几乎就是 20%,也就是我们预设的阈值。这说明我们通过上面的步骤,成功地将这个进程运行所占用的 CPU 资源限制在某个阈值之内了。
如果此时再启动另一个 hello 进程并将其 id 加入 tasks 文件,则两个进程会共享设定的 CPU 限制:
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
通过 cgroups 限制进程的 Memory
同样地,我们针对它占用的内存做如下操作:
1 | root@devstack:/sys/fs/cgroup/memory# mkdir hello |
上面的步骤会把进程 2428 说占用的内存阈值设置为 64K。超过的话,它会被杀掉。
限制进程的 I/O
运行命令:
1 | sudo dd if=/dev/sda1 of=/dev/null |
通过 iotop 命令看 IO (此时磁盘在快速转动),此时其写速度为 242M/s:
1 | TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND |
接着做下面的操作:
1 | root@devstack:/home/sammy# mkdir /sys/fs/cgroup/blkio/io |
结果,这个进程的IO 速度就被限制在 1Mb/s 之内了:
1 | TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND |
术语
cgroups 的术语包括:
- 任务(Tasks):就是系统的一个进程。
- 控制组(Control Group):一组按照某种标准划分的进程,比如官方文档中的Professor和Student,或是WWW和System之类的,其表示了某进程组。Cgroups中的资源控制都是以控制组为单位实现。一个进程可以加入到某个控制组。而资源的限制是定义在这个组上,就像上面示例中我用的 hello 一样。简单点说,cgroup的呈现就是一个目录带一系列的可配置文件。
- 层级(Hierarchy):控制组可以组织成hierarchical的形式,既一颗控制组的树(目录结构)。控制组树上的子节点继承父结点的属性。简单点说,hierarchy就是在一个或多个子系统上的cgroups目录树。
- 子系统(Subsystem):一个子系统就是一个资源控制器,比如CPU子系统就是控制CPU时间分配的一个控制器。子系统必须附加到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。Cgroup的子系统可以有很多,也在不断增加中。
Docker 对 cgroups 的使用
默认情况
默认情况下,Docker 启动一个容器后,会在 /sys/fs/cgroup 目录下的各个资源目录下生成以容器 ID 为名字的目录(group),比如:
1 | /sys/fs/cgroup/cpu/docker/03dd196f415276375f754d51ce29b418b170bd92d88c5e420d6901c32f93dc14 |
此时 cpu.cfs_quota_us 的内容为 -1,表示默认情况下并没有限制容器的 CPU 使用。在容器被 stopped 后,该目录被删除。
运行命令 docker run -d –name web41 –cpu-quota 25000 –cpu-period 100 –cpu-shares 30 training/webapp python app.py 启动一个新的容器,结果:
1 | root@devstack:/sys/fs/cgroup/cpu/docker/06bd180cd340f8288c18e8f0e01ade66d066058dd053ef46161eb682ab69ec24# cat cpu.cfs_quota_us |
Docker 会将容器中的进程的 ID 加入到各个资源对应的 tasks 文件中。表示 Docker 也是以上面的机制来使用 cgroups 对容器的 CPU 使用进行限制。
相似地,可以通过 docker run 中 mem 相关的参数对容器的内存使用进行限制:
1 | --cpuset-mems string MEMs in which to allow execution (0-3, 0,1) |
比如 docker run -d –name web42 –blkio-weight 100 –memory 10M –cpu-quota 25000 –cpu-period 2000 –cpu-shares 30 training/webapp python app.py:
1 | root@devstack:/sys/fs/cgroup/memory/docker/ec8d850ebbabaf24df572cb5acd89a6e7a953fe5aa5d3c6a69c4532f92b57410# cat memory.limit_in_bytes |
目前 docker 已经几乎支持了所有的 cgroups 资源,可以限制容器对包括 network,device,cpu 和 memory 在内的资源的使用,比如:
1 | root@devstack:/sys/fs/cgroup# find -iname ec8d850ebbabaf24df572cb5acd89a6e7a953fe5aa5d3c6a69c4532f92b57410 |
Docker run 命令中 cgroups 相关命令
1 | block IO: |
一些说明:
- cgroup 只能限制 CPU 的使用,而不能保证CPU的使用。也就是说, 使用 cpuset-cpus,可以让容器在指定的CPU或者核上运行,但是不能确保它独占这些CPU;cpu-shares 是个相对值,只有在CPU不够用的时候才其作用。也就是说,当CPU够用的时候,每个容器会分到足够的CPU;不够用的时候,会按照指定的比重在多个容器之间分配CPU。
- 对内存来说,cgroups 可以限制容器最多使用的内存。使用 -m 参数可以设置最多可以使用的内存。
Docker 网络概况
用一张图来说明 Docker 网络的基本概况:
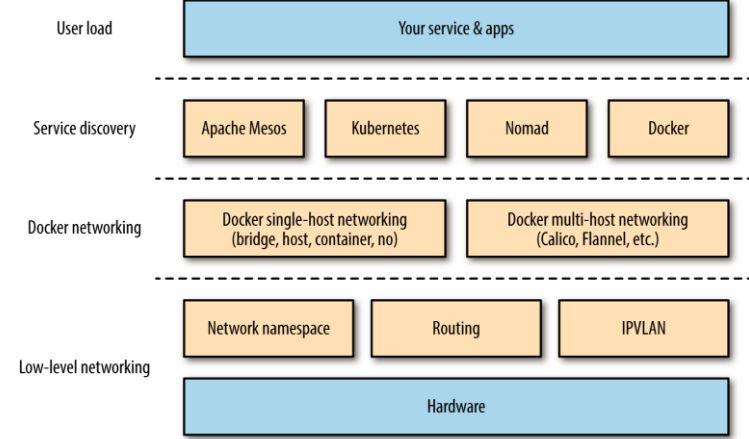
四种单节点网络模式
bridge 模式
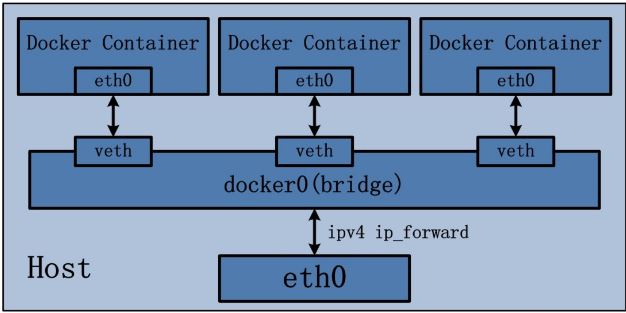
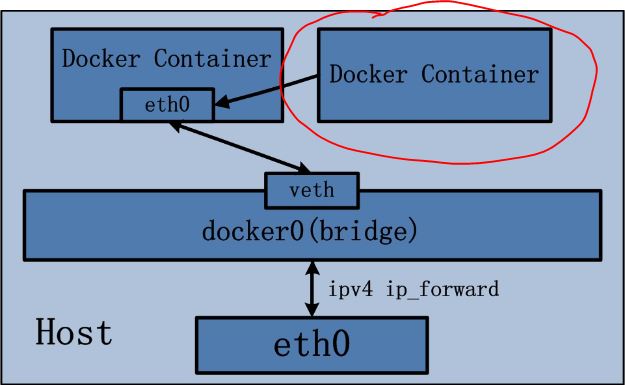
Docker 容器默认使用 bridge 模式的网络。其特点如下:
- 使用一个 linux bridge,默认为 docker0
- 使用 veth 对,一头在容器的网络 namespace 中,一头在 docker0 上
- 该模式下Docker Container不具有一个公有IP,因为宿主机的IP地址与veth pair的 IP地址不在同一个网段内
- Docker采用 NAT 方式,将容器内部的服务监听的端口与宿主机的某一个端口port 进行“绑定”,使得宿主机以外的世界可以主动将网络报文发送至容器内部
- 外界访问容器内的服务时,需要访问宿主机的 IP 以及宿主机的端口 port
- NAT 模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
- 容器拥有独立、隔离的网络栈;让容器和宿主机以外的世界通过NAT建立通信
iptables 的 SNTA 规则,使得从容器离开去外界的网络包的源 IP 地址被转换为 Docker 主机的IP地址:
1 | Chain POSTROUTING (policy ACCEPT) |
示意图:
Host 模式
定义:
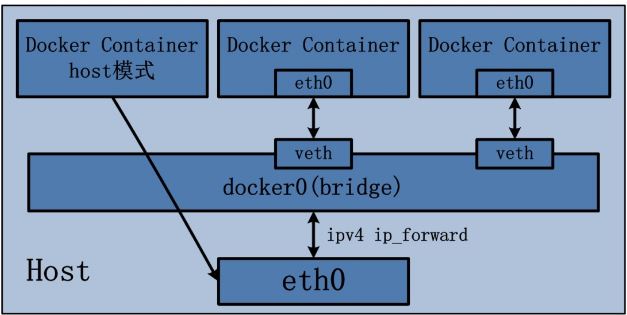
Host 模式并没有为容器创建一个隔离的网络环境。而之所以称之为host模式,是因为该模式下的 Docker 容器会和 host 宿主机共享同一个网络 namespace,故 Docker Container可以和宿主机一样,使用宿主机的eth0,实现和外界的通信。换言之,Docker Container的 IP 地址即为宿主机 eth0 的 IP 地址。其特点包括:
- 这种模式下的容器没有隔离的 network namespace
- 容器的 IP 地址同 Docker host 的 IP 地址
- 需要注意容器中服务的端口号不能与 Docker host 上已经使用的端口号相冲突
- host 模式能够和其它模式共存
示意图:
container 模式
定义:
Container 网络模式是 Docker 中一种较为特别的网络的模式。处于这个模式下的 Docker 容器会共享其他容器的网络环境,因此,至少这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
示意图:
none 模式
定义:
网络模式为 none,即不为 Docker 容器构造任何网络环境。一旦Docker 容器采用了none 网络模式,那么容器内部就只能使用loopback网络设备,不会再有其他的网络资源。Docker Container的none网络模式意味着不给该容器创建任何网络环境,容器只能使用127.0.0.1的本机网络。
to be continue …
参考
http://www.cnblogs.com/sammyliu/p/5875470.html
http://www.cnblogs.com/sammyliu/p/5878973.html
http://www.cnblogs.com/sammyliu/p/5886833.html