玩了很久的kafka,现在总结下吧,当然通过别人的文章来总结还是事半功倍的👿
架构图
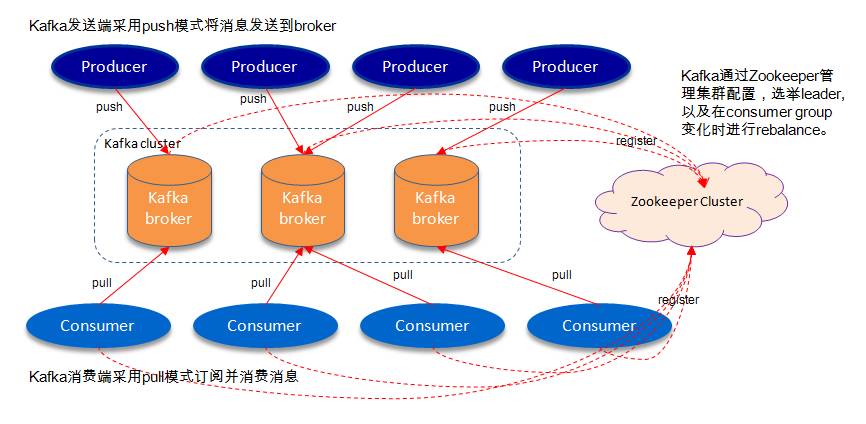
如上图,一个kafka架构包括若干个Producer(服务器日志、业务数据、web前端产生的page view等),若干个Broker(kafka支持水平扩展,一般broker数量越多集群的吞吐量越大),若干个consumer group,一个Zookeeper集群(kafka通过Zookeeper管理集群配置、选举leader、consumer group发生变化时进行rebalance)。
名称解释
- Broker: 消息中间件处理节点(服务器),一个节点就是一个broker,一个Kafka集群由一个或多个broker组成
- Topic: Kafka对消息进行归类,发送到集群的每一条消息都要指定一个topic
- Partition: 物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的
- Producer: 生产者,负责发布消息到broker
- Consumer: 消费者,从broker读取消息
- ConsumerGroup: 每个consumer属于一个特定的consumer group,可为每个consumer指定group name,若不指定,则属于默认的group,一条消息可以发送到不同的consumer group,但一个consumer group中只能有一个consumer能消费这条消息
关系解释
Topic & Partition
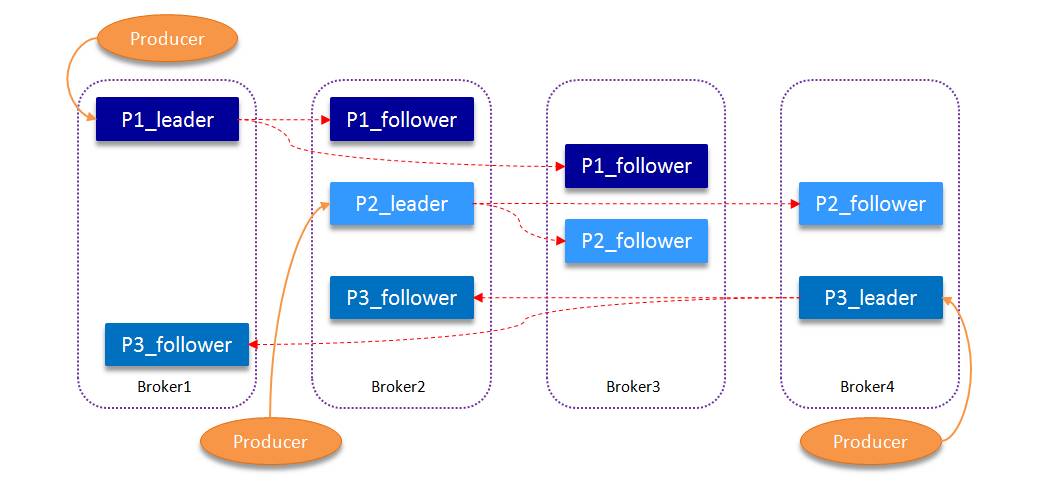
一个topic为一类消息,每条消息必须指定一个topic。物理上,一个topic分成一个或多个partition,每个partition有多个副本分布在不同的broker中,如下图。
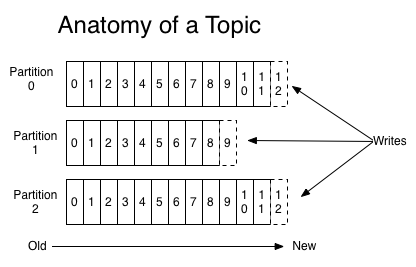
每个partition在存储层面是一个append log文件,发布到此partition的消息会追加到log文件的尾部,为顺序写人磁盘(顺序写磁盘比随机写内存的效率还要高)。每条消息在log文件中的位置成为offset(偏移量),offset为一个long型数字,唯一标记一条消息。如下图
每个消费者唯一保存的元数据是offset值,这个位置完全为消费者控制,因此消费者可以采用任何顺序来消费记录,如下图
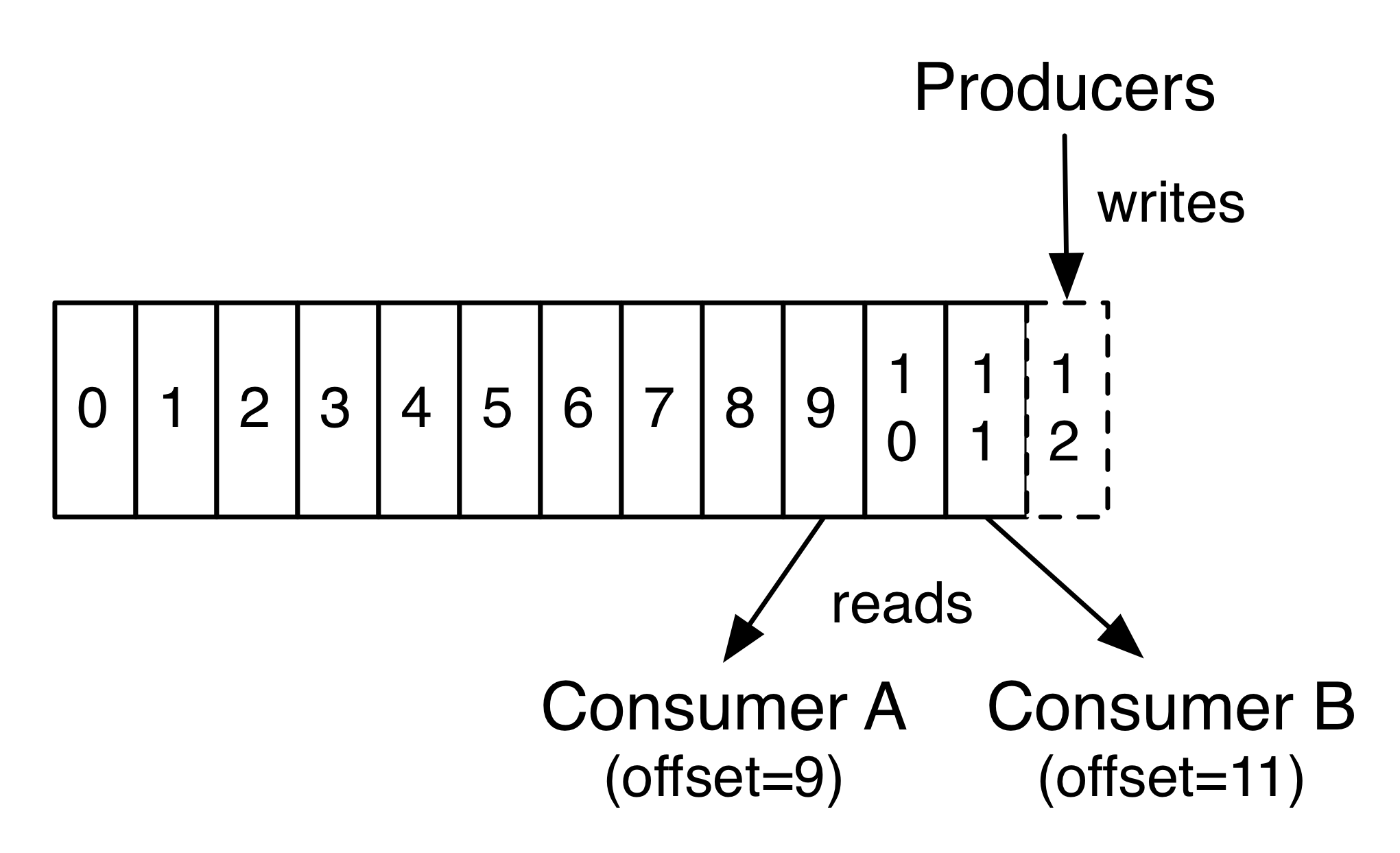
kafka中只能保证partition中记录是有序的,而不保证topic中不同partition的顺序
Consumer group & consumer
一个消费组由一个或多个消费者实例组成,便于扩容与容错。
kafka是发布与订阅模式,这个订阅者是消费组,而不是消费者实例。每一条消息只会被同一个消费组里的一个消费者实例消费,不同的消费组可以同时消费同一条消息,如下图

为了实现传统的消息队列中消息只被消费一次的语义,kafka保证同一个消费组里只有一个消费者会消费一条消息,kafka还允许不同的消费组同时消费一条消息,这一特性可以为消息的多元化处理提供了支持,kafka的设计理念之一就是同时提供离线处理和实时处理,因此,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作的消费者实例在不同consumer group 即可
Consumer Rebalance
kafka保证了同一个消费组中只有一个消费者实例会消费某条消息,实际上,kafka保证的是稳定状态下每一个消费者实例只会消费一个或多个特定partition数据,而某个partition的数据只会被某一特定的consumer实例消费,这样设计的劣势是无法让同一个消费组里的consumer均匀消费,优势是每个consumer不用跟大量的broker通信,减少通信开销,也降低了分配难度。而且,同一个partition数据是有序的,保证了有序被消费。根据consumer group中的consumer数量和partition数量,可以分为以下3种情况:
- 若consumer group中的consumer数量少于partition数量,则至少有1个consumer会消费多个partition数据
- 若consumer group中的consumer数量多于partition数量,则会有部分consumer无法消费该topic中任何一条消息
- 若consumer group中的consumer数量等于partition数量,则正好一个consumer消费一个partition数据
实例
以一个实例结束这篇文章
创建一个kafka-topic,它有4个分片。
1 | kafka-topics.sh --create --zookeeper zk:2181 --replication-factor 1 --partitions 4 --topic kafka-topic |
编写一个生产者
输出1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27Sun Jul 22 07:17:11 UTC 2018,kafka.apache.org,192.168.14.203
publish to partition 2
offset 0
Sun Jul 22 07:17:14 UTC 2018,kafka.apache.org,192.168.14.134
publish to partition 0
offset 0
Sun Jul 22 07:17:16 UTC 2018,kafka.apache.org,192.168.14.150
publish to partition 0
offset 1
Sun Jul 22 07:17:18 UTC 2018,kafka.apache.org,192.168.14.49
publish to partition 2
offset 1
Sun Jul 22 07:17:20 UTC 2018,kafka.apache.org,192.168.14.55
publish to partition 2
offset 2
Sun Jul 22 07:17:22 UTC 2018,kafka.apache.org,192.168.14.172
publish to partition 2
offset 3
Sun Jul 22 07:17:24 UTC 2018,kafka.apache.org,192.168.14.122
publish to partition 1
offset 0
Sun Jul 22 07:17:26 UTC 2018,kafka.apache.org,192.168.14.237
publish to partition 3
offset 0
Sun Jul 22 07:17:28 UTC 2018,kafka.apache.org,192.168.14.95
publish to partition 2
offset 4
基本都均匀写到不同的分片上
接下来是一个消费者,它启动三个线程代表三个消费者去消费
输出
1 | 0: {partition=1, offset=20, value=Sun Jul 22 07:20:12 UTC 2018,kafka.apache.org,192.168.14.141} |
每一行开头的序号代表的是消费者的序号,很明显0号消费者消费了0和1分片,1号消费者消费2号分片,2号消费者消费3号分片
接下来试下加大消费者等于分片数即4个消费者看看
输出1
2
3
4
5
6
7
8
9
10
110: {partition=0, offset=66, value=Sun Jul 22 07:27:06 UTC 2018,kafka.apache.org,192.168.14.99}
3: {partition=3, offset=90, value=Sun Jul 22 07:27:08 UTC 2018,kafka.apache.org,192.168.14.222}
0: {partition=0, offset=67, value=Sun Jul 22 07:27:10 UTC 2018,kafka.apache.org,192.168.14.106}
2: {partition=2, offset=70, value=Sun Jul 22 07:27:12 UTC 2018,kafka.apache.org,192.168.14.175}
0: {partition=0, offset=68, value=Sun Jul 22 07:27:14 UTC 2018,kafka.apache.org,192.168.14.163}
1: {partition=1, offset=70, value=Sun Jul 22 07:27:16 UTC 2018,kafka.apache.org,192.168.14.176}
3: {partition=3, offset=91, value=Sun Jul 22 07:27:18 UTC 2018,kafka.apache.org,192.168.14.228}
2: {partition=2, offset=71, value=Sun Jul 22 07:27:20 UTC 2018,kafka.apache.org,192.168.14.55}
1: {partition=1, offset=71, value=Sun Jul 22 07:27:22 UTC 2018,kafka.apache.org,192.168.14.40}
1: {partition=1, offset=72, value=Sun Jul 22 07:27:24 UTC 2018,kafka.apache.org,192.168.14.135}
0: {partition=0, offset=69, value=Sun Jul 22 07:27:26 UTC 2018,kafka.apache.org,192.168.14.249}
很明显,每个消费者跟每个分片是一一对应的。
再看看消费者多余分片的情况,这次把消费者加大到6个
输出
1 | 2: {partition=2, offset=90, value=Sun Jul 22 07:29:44 UTC 2018,kafka.apache.org,192.168.14.148} |
显然,只是看到四个消费者消费四个分片,其余消费者没有参与到消费中去。
总结
kafka是一个高可用高吞吐的分布式消息组件,多分片可以提供多消费者多产生者的吞吐,多个分组可以满足多个应用对同一个消息队列的使用要求而互不干扰,同一分组消费者还能基本保证消息只消费一次。
参考 https://zhuanlan.zhihu.com/p/38269875
使用的实例可到这个链接获取,还提供docker运行环境哦