几个礼拜之前我们开始一系列对于JavaScript以及其本质工作原理的深入挖掘:我们认为通过了解JavaScript的构建方式以及它们是如何共同合作的,你就能够写出更好的代码以及应用。
这个系列的第一篇博客专注于介绍对于引擎,运行时以及调用栈的概述。第二篇博客近距离地检测了Google V8 引擎的内部并且提供了一些如何写出更好的JavaScript代码的建议。
在第三篇博客中,我们将会讨论另外一个关键的话题。这个话题由于随着编程语言的逐渐成熟和复杂化,越来越被开发者所忽视,这个话题就是在日常工作中使用到的——内存管理。
概述
语言,比如C,具有低层次的内存管理方法,比如malloc()以及free()。开发者利用这些方法精确地为操作系统分配以及释放内存。
同时,JavaScript会在创建一些变量(对象,字符串等等)的时候分配内存,并且会在这些不被使用之后“自动地”释放这些内存,这个过程被称为垃圾收集。这个看起来“自动化的”特性其实就是产生误解的原因,并且给JavaScript(以及其他高层次语言)开发者一个假象,他们不需要关心内存管理。大错特错。
即使是使用高层次语言,开发者应该对于内存管理有一定的理解(或者最基本的理解)。有时候自动的内存管理会存在一些问题(比如一些bug或者垃圾收集器的一些限制等等),对于这些开发者必须能够理解从而能够合适地处理(或者使用最小的代价以及代码债务去绕过这个问题)。
内存生命周期
不管你在使用什么编程语言,内存的生命周期基本上都是一样的:
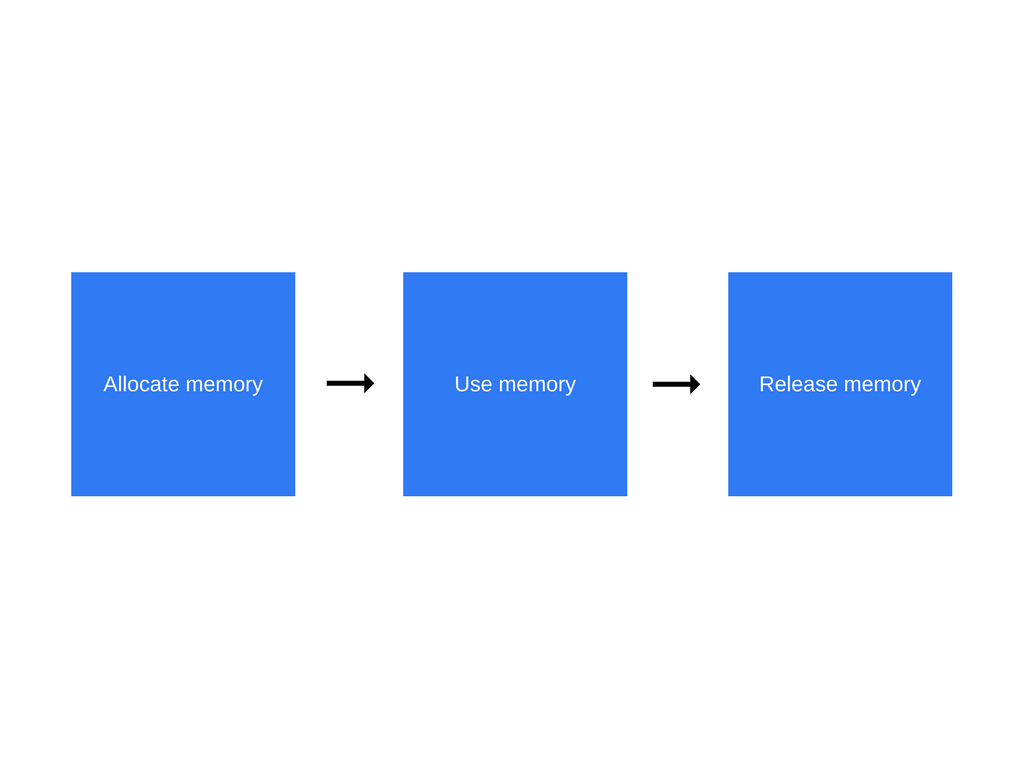
下面是对于周期中每一步所发生的情况的概述:
- 分配内存——操作系统为你的程序分配内存并且允许其使用。在低层次语言中(比如C),这正是开发者应该处理的操作。在高层次的语言,然而,就由语言帮你实现了。
- 使用内存——当你的程序确实在使用之前分配的内存的阶段。当你在使用你代码里面分配的变量的时候会发生读以及写操作。
- 释放内存——这个阶段就是释放你不再需要的内存,从而这些内存被释放并且能够再次被使用。和分配内存操作一样,这在低层次的语言也是开发者需要明确的操作。
对于调用栈以及内存堆有一个快速的概念认识,你可以阅读我们关于这个话题的第一篇博客。
什么是内存?
在我们讲述JavaScript内存之前,我们将简要地讨论一下内存是什么以及它们是如何在 nutshell 中工作的。
在硬件层次上,计算机内存由大量的 寄存器 组成。每一个寄存器都包含一些晶体管并且能够存储一比特。单独的寄存器可以通过独特的标识符去访问,因此我们能够读取以及重写它们。因此,从概念上来说,我们可以认为我们的整个计算机内存就是一个我们能够读写的大型比特数组。
因为作为人类,我们不擅长直接基于比特进行思考以及算术,我们将它们组织成大规模群组,它们在一起可以代表一个数字。8个比特称为一个字节。除了字节,还有词(有时候是16比特,有时候是32比特)。
内存中存储了很多东西:
- 所有程序使用的变量和其他数据
- 程序的代码,包括操作系统的代码。
编译器和操作系统共同合作为你处理大部分的内存管理,但是我们建议你应该了解其内部的运行原理。
当你编译你的代码的时候,编译器将会检查原始数据类型并且提前计算好它们需要多少内存。需要的内存被分配给程序,这被称为栈空间。这些被分配给变量的空间被称为栈空间,因为一旦函数被调用,它们的内存就会增加到现有内存的上面。当它们终止的时候,它们就会以后进先出(LIFO)的顺序移除。比如,考虑下面的声明。
1 | int n; // 4 bytes |
编译器能够立即计算出代码需要
4 + 4 × 4 + 8 = 28 字节
那就是它如何对于现有的整形以及双浮点型工作。大约20年前,整形典型都是2个字节,双浮点型是4个字节。你的代码不应该取决于当下基本数据类型的大小。
编译器将会插入能够与操作系统交互的代码,从而在栈上获取你需要存储变量需要的字节数。
在上述的例子中,编译器知道每一个变量的准确的内存地址。事实上,无论我们何时写变量 n ,这都会在内部转化为类似于“内存地址 4127963”的东西。
注意如果我们希望在这访问 x[4] 我们将会需要访问和 m 相关联的数据。这是因为我们在访问数组里面并不存在的元素——它比数组实际分配的最后一个元素 x[3] 要多4个字节,并且最后可能是阅读(或者重写)一些 m 的比特。这将很可能给程序的其他部分带来一些不良的后果。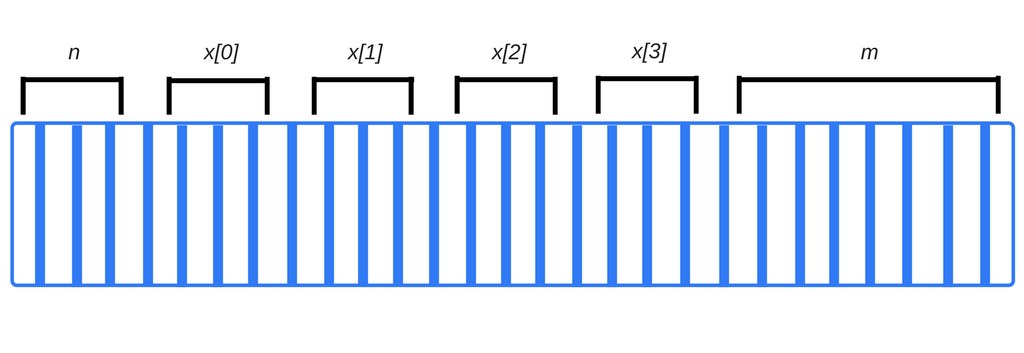
当函数调用其它函数的时候,当它被调用的时候都会获取它自己的堆栈块。它在那保存了它所有的局部变量,但是还会有一个程序计数器记录它执行的位置。当这个函数执行完毕,它的内存块就可以再次用于其他目的。
动态分配
不幸的是,当我们在编译的时候不知道变量需要多少内存的话事情可能就不那么简单。假设我们想做下面的事情:1
2
3
4
5
6
int n = readInput(); // reads input from the user
...
// create an array with "n" elements
在此,在编译阶段中,编译器就没有办法知道数组需要多少内存,因为它取决于用户的输入。
因此,它就不能够为栈上的变量分配空间。相反,我们的程序需要明确地询问操作运行时需要的空间数量。这个内存是从堆空间中分配出来的。动态内存和静态内存分配的区别总结如下表格:
为了深入地理解动态内存分配是如何工作的,我们需要花费更多的时间在指针,这个可能有点偏离这篇博客的话题。如果你感兴趣了解更多,在评论里面告诉我,我将会在后续的博客中挖掘更多的细节。
JavaScript中的分配
现在我们将解释JavaScript中的第一步(分配内存)。
JavaScript 将开发者从内存分配的处理中解放出来——JavaScript自身可以利用声明变量来完成这些任务。
1 | var n = 374; // allocates memory for a number |
一些函数调用也会导致一些对象的分配:
1 |
|
能够分配新的值或者对象的方法:
1 | var s1 = 'sessionstack'; |
在JavaScript中使用内存
基本上在JavaScript中分配内存,就意味着在其中读写。
这可以通过对一个变量或者一个对象的属性甚至是向函数传递一个参数来完成。
当内存不再需要的时候释放它
大多数的内存管理的问题就来自于这个阶段。
最困难的任务就是如何知道何时被分配的不再需要了。它经常需要开发者决定在程序的什么地方某段内存不再需要了并且对其进行释放。
高层次语言内嵌了一个称为垃圾收集器的软件,他的任务就是跟踪内存分配并且用于需找不再需要的分配过的内存,并且自动地对其进行释放。
不幸的是,这个过程是一个近似,因为知道是否某块内存是需要的问题是不可决定的(无法通过算法解决)
大多数的垃圾收集器通过收集再也无法访问的内存工作,比如:指向它的所有变量都超出了作用域。然而,这依然是对于可以收集的内存空间的预估,因为在任何位置仍可能一些变量在作用域内指向这个内存,然而它再也不能被访问了。
垃圾收集器
由于找到一些是“不再需要的”是不可决定的事实,垃圾收集实现了对一般问题的解决方案的限制。这一节将会解释理解主要的垃圾收集算法以及它们的限制的需要注意的事项。
内存引用
垃圾收集算法依赖的主要概念之一就是引用。
在内存管理的上下文中,一个对象被称为是对于另外一个对象的引用,如果前者可以访问后者(隐含或明确的)。例如,一个JavaScript对象都有一个指向其原型的引用(隐含的引用)
在这个上下文中,“对象”的概念扩展到比普通的JavaScript对象要广并且包括函数作用域(或者全局词法作用域)。
词法作用域定义了变量名称是如何在嵌套函数中解析的:内部函数包含了父函数的作用域即使父函数已经返回了。
基于引用计数的垃圾收集器
这是最简单的垃圾收集器算法。如果没有引用指向这个对象的时候,这个对象就被认为是“可以作为垃圾收集”。
请看如下代码:
1 | var o1 = { |
循环在产生问题
当遇到循环的时候就会有一个限制。在下面的实例之中,创建两个对象,并且互相引用,因此就会产生一个循环。当函数调用结束之后它们会走出作用域之外,因此它们就没什么用并且可以被释放。但是,基于引用计数的算法认为这两个对象都会被至少引用一次,所以它俩都不会被垃圾收集器收集。
1 | function f() { |

标记-清除算法
为了决定哪个对象是需要的,算法会决定是否这个对象是可访问的。
这个算法由以下步骤组成:
- 这个垃圾收集器构建一个“roots”列表。Root是全局变量,被代码中的引用所保存。在 JavaScript中,“window”就是这样的作为root的全局变量的例子。
- 所有的root都会被监测并且被标志成活跃的(比如不是垃圾)。所有的子代也会递归地被监测。所有能够由root访问的一切都不会被认为是垃圾。
- 所有不再被标志成活跃的内存块都被认为是垃圾。这个收集器现在就可以释放这些内存并将它们返还给操作系统。
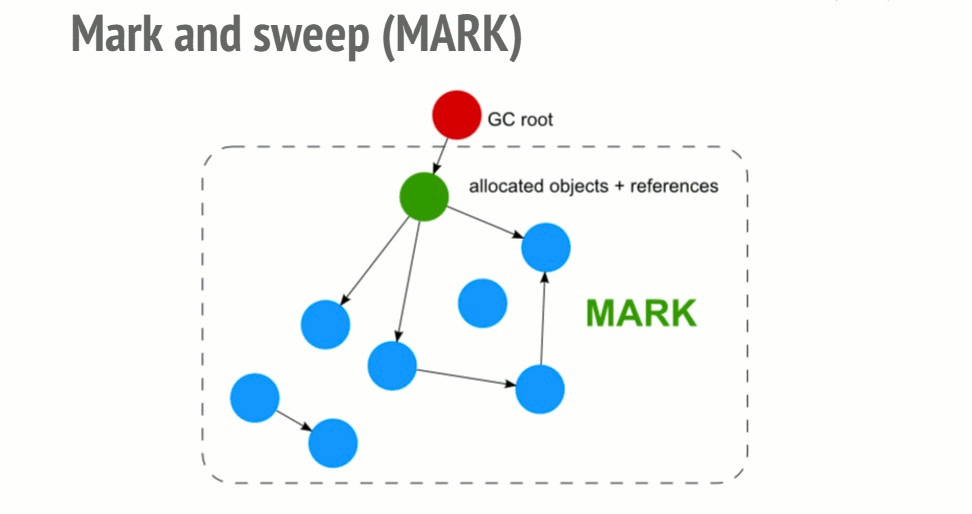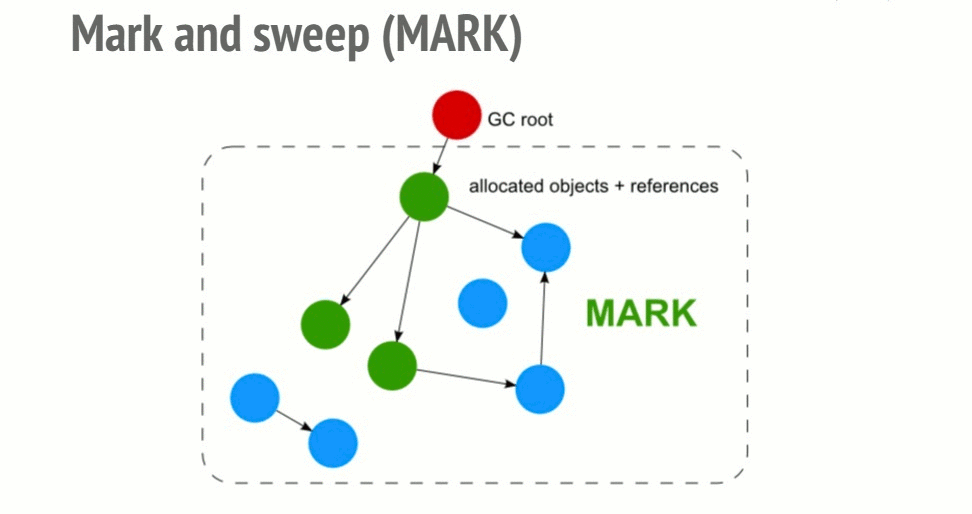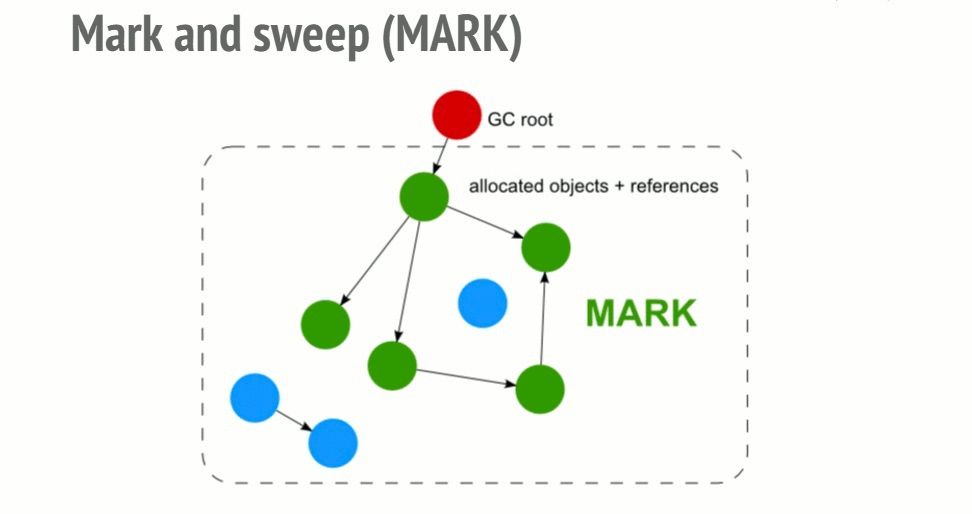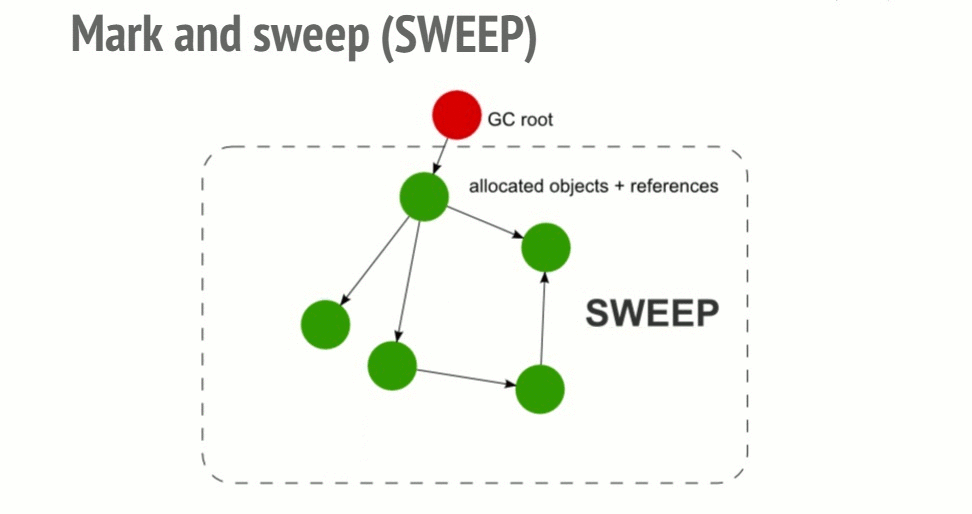
这个算法要优于之前的因为“一个具有0引用的对象”可以让一个对象不能够再被访问。但是相反的却不一定成立,比如我们遇到循环的时候。
在2012年,所有的现代浏览器都使用标记-清除垃圾收集器。过去几年,JavaScript垃圾收集(代数/增量/并行/并行垃圾收集)领域的所有改进都是对该算法(标记和扫描)的实现进行了改进,但并没有对垃圾收集算法本身的改进, 其目标是确定一个对象是否可达。
在这篇文章中,你可以得到更多关于垃圾收集追踪并且也覆盖到了关于标记-清除算法的优化。
循环不再是一个问题
在上述的第一个例子中,在函数调用返回之后,这两个对象不能够被全局对象所访问。因此,垃圾收集器就会发现它们不能够被访问了。
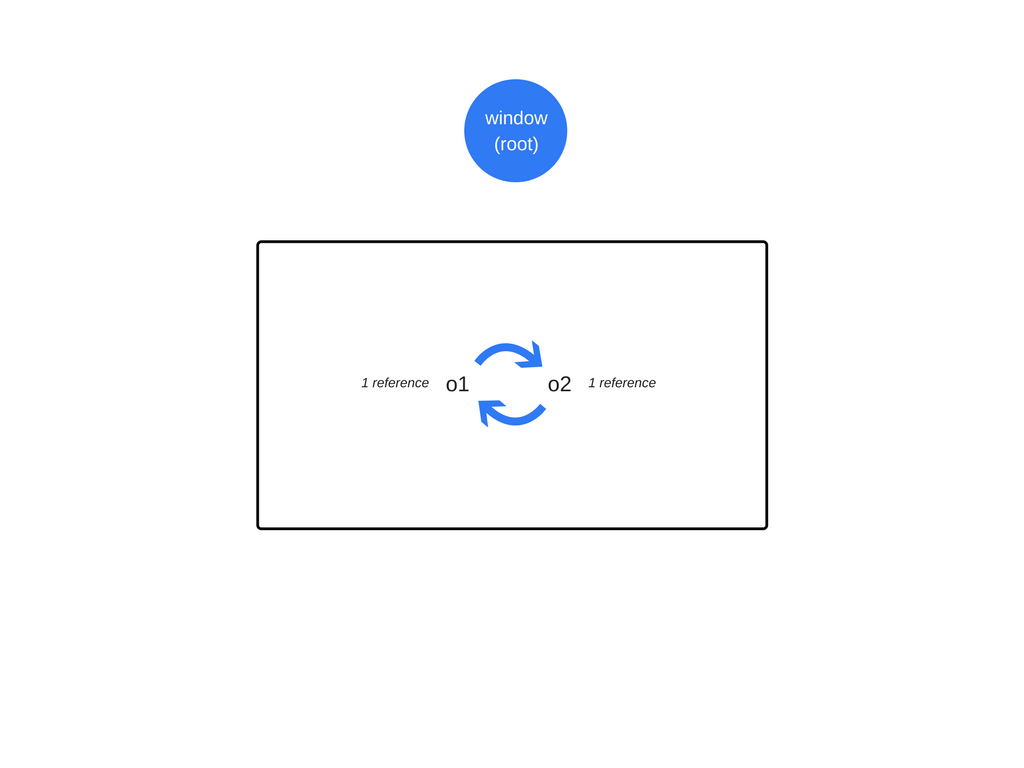
即使在这两个对象之间存在着引用,它们再也不能从root访问了。
列举垃圾收集器的直观行为
虽然垃圾收集器很方便,但它们自己也有自己的代价。 其中一个是非确定论。 换句话说,GC是不可预测的。 你不能真正地告诉你什么时候会收集。 这意味着在某些情况下,程序会使用实际需要的更多内存。 在其他情况下,特别敏感的应用程序可能会引起短暂暂停。 虽然非确定性意味着在执行集合时无法确定,但大多数GC实现共享在分配期间执行收集遍历的常见模式。 如果没有执行分配,大多数GC保持空闲状态。 考虑以下情况:
- 执行相当大的一组分配。
- 这些元素中的大多数(或全部)被标记为不可访问(假设我们将指向我们不再需要的缓存的引用置空)。
- 不再执行分配。
在这种情况下,大多数GC不会再运行收集处理。换句话说,即使存在对于收集器来说不可访问的引用,它们也不会被收集器所认领。严格意义来说这并不是泄露,但是依然会导致比平常更多的内存使用。
什么是内存泄露?
实质上,内存泄漏可以被定义为应用程序不再需要的内存,但是由于某些原因不会返回到操作系统或可用内存池。

编程语言有支持管理内存的不同方法。 然而,某块内存是否被使用实际上是一个不可判定的问题。 换句话说,只有开发人员可以清楚一个内存是否可以返回到操作系统。
某些编程语言提供了帮助开发者执行此操作的功能。其他的则期望开发人员能够完全明确何时使用一块内存。 维基百科有关于手动和自动内存管理的好文章。
四种常见的JavaScript泄露
全局变量
JavaScript 使用一种有趣的方式处理未声明的变量:一个未声明变量的引用会在全局对象内部产生一个新的变量。在浏览器的情况,这个全局变量就会是window。换句话说:
1 | function foo(arg) { |
等同于:
1 | function foo(arg) { |
如果bar被期望仅仅在foo函数作用域内保持对变量的引用,并且你忘记使用var去声明它,一个意想不到的全局变量就产生了。
在这个例子中,泄露就仅仅是一个字符串并不会带来太多危害,但是它可能会变得更糟。
另外一种可能产生意外的全局变量的方式是:
1 | function foo() { |
为了阻止这些错误的发生,可以在js文件头部添加’use strict’。这将会使用严格模式来解析 JavaScript 从而阻止意外的全局变量。了解更多关于JavaScript执行的模式。
即使我们讨论了未预期的全局变量,但仍然有很多代码用显式的全局变量填充。 这些定义是不可收集的(除非分配为null或重新分配)。 特别是,用于临时存储和处理大量信息的全局变量值得关注。 如果你必须使用全局变量来存储大量数据,请确保在完成之后将其分配为null或重新分配。
被遗忘的计时器和回调
setInterval 在 JavaScript 中是经常被使用的。
大多数提供观察者和其他模式的回调函数库都会在调用自己的实例变得无法访问之后对其任何引用也设置为不可访问。 但是在setInterval的情况下,这样的代码很常见:
1 | var serverData = loadData(); |
这个例子说明了计时器可能发生的情况:计时器可能会产生再也不被需要的节点或者数据的引用。
renderer所代表的对象在未来可能被移除,让部分interval 处理器中代码变得不再被需要。然而,这个处理器不能够被收集因为interval依然活跃的(这个interval需要被停止从而表面这种情况)。如果这个interval处理器不能够被收集,那么它的依赖也不能够被收集。这意味这存储大量数据的severData也不能够被收集。
在这种观察者的情况下,做出准确的调用从而在不需要它们的时候立即将其移除是非常重要的(或者相关的对象被置为不可访问的)。
过去,以前特别重要的是某些浏览器(好的老IE 6)无法管理好循环引用(有关更多信息,请参见下文)。 如今,大多数浏览器一旦观察到的对象变得无法访问,就能收集观察者处理器,即使侦听器没有被明确删除。 但是,在处理对象之前,明确删除这些观察者仍然是一个很好的做法。 例如:
1 | var element = document.getElementById('launch-button'); |
当今,现在浏览器(报错IE和Edge)都使用了现代的垃圾收集算法,其能够检测到这些循环并且进行适宜的处理。换句话说,再也不是严格需要在将节点置为不可访问之前调用removeEventListener 。
框架和库(如jQuery)在处理节点之前(在为其使用特定的API时)会删除侦听器。 这是由库内部处理的,这也确保没有泄漏,即使在有问题的浏览器下运行,如…是的,IE 6。
闭包
JavaScript 开发的一个关键方面是闭包:一个可以访问外部(封闭)函数变量的内部函数。 由于JavaScript运行时的实现细节,可以通过以下方式泄漏内存:
1 | var theThing = null; |
这个代码段会做一件事情:每次 replaceThing 被调用时,theThing 都会获取一个一个包含一个大数组的以及一个新的闭包(someMethod)。同时,unused 会保持一个指向originalThing引用的闭包(从上一个调用的theThing到replaceThing)。可能已经很迷惑了,是不是?重要的事情是一旦在相同的父级作用域为闭包产生作用域,这个作用域就会被共享。
在这种情况下,为someMethod闭包产生的作用域就会被unused 所共享。unused 具有对于originaThing的引用。即使 unused 不再被使用,someMethod依然可以通过replaceThing作用域之外的theThing来使用。并且由于somethod和unused 共享闭包作用域,unused指向originalThing的引用强迫其保持活跃(两个闭包之间的整个共享作用域)。这将会阻止垃圾手机。
当这个代码段重复运行时,可以观察到内存使用量的稳定增长。 当GC运行时,这不会变小。 实质上,创建了一个关闭的链接列表(其root以TheThing变量的形式),并且这些闭包的范围中的每一个都对大数组进行间接引用,导致相当大的泄漏。
这个问题由Meteor团队发现,他们有一篇很好的文章,详细描述了这个问题。
DOM 之外的引用
有时将DOM节点存储在数据结构中可能是有用的。 假设要快速更新表中的几行内容。 存储对字典或数组中每个DOM行的引用可能是有意义的。 当发生这种情况时,会保留对同一DOM元素的两个引用:一个在DOM树中,另一个在字典中。 如果将来某个时候您决定删除这些行,则需要使两个引用置为不可访问。
1 | var elements = { |
还有一个额外的考虑,当涉及对DOM树内部的内部或叶节点的引用时,必须考虑这一点。 假设你在JavaScript代码中保留对表格特定单元格(<td>标记)的引用。 有一天,你决定从DOM中删除该表,但保留对该单元格的引用。 直观地,可以假设GC将收集除了该单元格之外的所有内容。 实际上,这不会发生:该单元格是该表的子节点,并且孩子们保持对父代的引用。 也就是说,从JavaScript代码引用表格单元会导致整个表保留在内存中。 保持对DOM元素的引用时需要仔细考虑。