压缩列表(ziplist)是列表键和哈希键的底层实现之一。
当一个列表键只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
压缩列表的构成
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。
图 7-1 展示了压缩列表的各个组成部分, 表 7-1 则记录了各个组成部分的类型、长度、以及用途。
表 7-1 压缩列表各个组成部分的详细说明
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配, 或者计算 zlend 的位置时使用。 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节: 通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量: 当这个属性的值小于 UINT16_MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量; 当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entryX | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
图 7-2 展示了一个压缩列表示例:
- 列表 zlbytes 属性的值为 0x50 (十进制 80), 表示压缩列表的总长为 80 字节。
- 列表 zltail 属性的值为 0x3c (十进制 60), 这表示如果我们有一个指向压缩列表起始地址的指针 p , 那么只要用指针 p 加上偏移量 60 , 就可以计算出表尾节点 entry3 的地址。
- 列表 zllen 属性的值为 0x3 (十进制 3), 表示压缩列表包含三个节点。

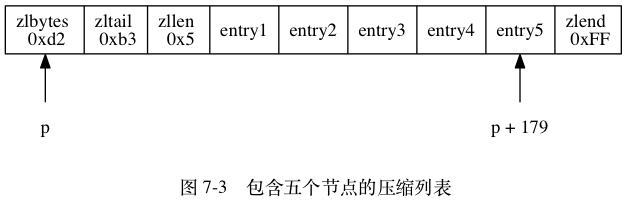
图 7-3 展示了另一个压缩列表示例:
- 列表 zlbytes 属性的值为 0xd2 (十进制 210), 表示压缩列表的总长为 210 字节。
- 列表 zltail 属性的值为 0xb3 (十进制 179), 这表示如果我们有一个指向压缩列表起始地址的指针 p , 那么只要用指针 p 加上偏移量 179 , 就可以计算出表尾节点 entry5 的地址。
- 列表 zllen 属性的值为 0x5 (十进制 5), 表示压缩列表包含五个节点。
压缩列表节点的构成
每个压缩列表节点可以保存一个字节数组或者一个整数值, 其中, 字节数组可以是以下三种长度的其中一种:
- 长度小于等于 63 (2^{6}-1)字节的字节数组;
- 长度小于等于 16383 (2^{14}-1) 字节的字节数组;
- 长度小于等于 4294967295 (2^{32}-1)字节的字节数组;
而整数值则可以是以下六种长度的其中一种:
- 4 位长,介于 0 至 12 之间的无符号整数;
- 1 字节长的有符号整数;
- 3 字节长的有符号整数;
- int16_t 类型整数;
- int32_t 类型整数;
- int64_t 类型整数。
每个压缩列表节点都由 previous_entry_length 、 encoding 、 content 三个部分组成, 如图 7-4 所示。
接下来的内容将分别介绍这三个组成部分。
previous_entry_length
节点的 previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。
previous_entry_length 属性的长度可以是 1 字节或者 5 字节:
- 如果前一节点的长度小于 254 字节, 那么 previous_entry_length 属性的长度为 1 字节: 前一节点的长度就保存在这一个字节里面。
- 如果前一节点的长度大于等于 254 字节, 那么 previous_entry_length 属性的长度为 5 字节: 其中属性的第一字节会被设置为 0xFE (十进制值 254), 而之后的四个字节则用于保存前一节点的长度。
图 7-5 展示了一个包含一字节长 previous_entry_length 属性的压缩列表节点, 属性的值为 0x05 , 表示前一节点的长度为 5 字节。
图 7-6 展示了一个包含五字节长 previous_entry_length 属性的压缩节点, 属性的值为 0xFE00002766 , 其中值的最高位字节 0xFE 表示这是一个五字节长的 previous_entry_length 属性, 而之后的四字节 0x00002766 (十进制值 10086 )才是前一节点的实际长度。
因为节点的 previous_entry_length 属性记录了前一个节点的长度, 所以程序可以通过指针运算, 根据当前节点的起始地址来计算出前一个节点的起始地址。
举个例子, 如果我们有一个指向当前节点起始地址的指针 c , 那么我们只要用指针 c 减去当前节点 previous_entry_length 属性的值, 就可以得出一个指向前一个节点起始地址的指针 p , 如图 7-7 所示。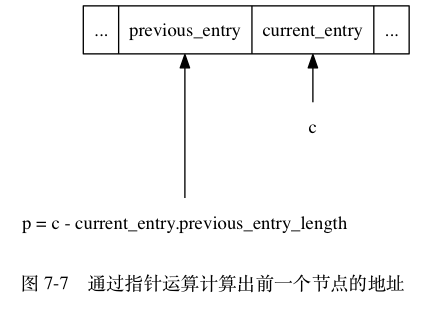
压缩列表的从表尾向表头遍历操作就是使用这一原理实现的: 只要我们拥有了一个指向某个节点起始地址的指针, 那么通过这个指针以及这个节点的 previous_entry_length 属性, 程序就可以一直向前一个节点回溯, 最终到达压缩列表的表头节点。
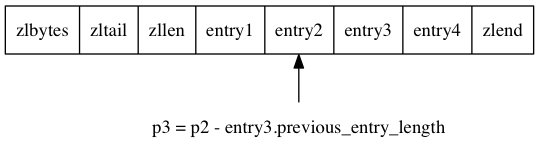
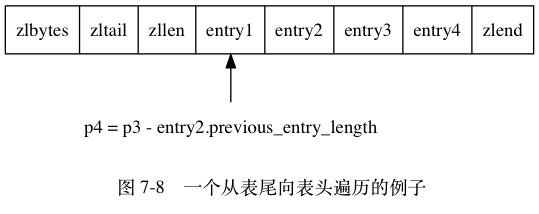
图 7-8 展示了一个从表尾节点向表头节点进行遍历的完整过程:
- 首先,我们拥有指向压缩列表表尾节点 entry4 起始地址的指针 p1 (指向表尾节点的指针可以通过指向压缩列表起始地址的指针加上 zltail 属性的值得出);
- 通过用 p1 减去 entry4 节点 previous_entry_length 属性的值, 我们得到一个指向 entry4 前一节点 entry3 起始地址的指针 p2 ;
- 通过用 p2 减去 entry3 节点 previous_entry_length 属性的值, 我们得到一个指向 entry3 前一节点 entry2 起始地址的指针 p3 ;
- 通过用 p3 减去 entry2 节点 previous_entry_length 属性的值, 我们得到一个指向 entry2 前一节点 entry1 起始地址的指针 p4 , entry1 为压缩列表的表头节点;
- 最终, 我们从表尾节点向表头节点遍历了整个列表。


encoding
节点的 encoding 属性记录了节点的 content 属性所保存数据的类型以及长度:
- 一字节、两字节或者五字节长, 值的最高位为 00 、 01 或者 10 的是字节数组编码: 这种编码表示节点的 content 属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录;
- 一字节长, 值的最高位以 11 开头的是整数编码: 这种编码表示节点的 content 属性保存着整数值, 整数值的类型和长度由编码除去最高两位之后的其他位记录;
表 7-2 记录了所有可用的字节数组编码, 而表 7-3 则记录了所有可用的整数编码。 表格中的下划线 _ 表示留空, 而 b 、 x 等变量则代表实际的二进制数据, 为了方便阅读, 多个字节之间用空格隔开。
表 7-2 字节数组编码
| 编码 | 编码长度 | content 属性保存的值 |
|---|---|---|
| 00bbbbbb | 1 字节 | 长度小于等于 63 字节的字节数组。 |
| 01bbbbbb xxxxxxxx | 2 字节 | 长度小于等于 16383 字节的字节数组。 |
| 10______ aaaaaaaa bbbbbbbb cccccccc dddddddd | 5 字节 | 长度小于等于 4294967295 的字节数组。 |
表 7-3 整数编码
| 编码 | 编码长度 | content 属性保存的值 |
|---|---|---|
| 11000000 | 1 字节 | int16_t 类型的整数。 |
| 11010000 | 1 字节 | int32_t 类型的整数。 |
| 11100000 | 1 字节 | int64_t 类型的整数。 |
| 11110000 | 1 字节 | 24 位有符号整数。 |
| 11111110 | 1 字节 | 8 位有符号整数。 |
| 1111xxxx | 1 字节 | 使用这一编码的节点没有相应的 content 属性, 因为编码本身的 xxxx 四个位已经保存了一个介于 0 和 12 之间的值, 所以它无须 content 属性。 |
content
节点的 content 属性负责保存节点的值, 节点值可以是一个字节数组或者整数, 值的类型和长度由节点的 encoding 属性决定。
图 7-9 展示了一个保存字节数组的节点示例:
- 编码的最高两位 00 表示节点保存的是一个字节数组;
- 编码的后六位 001011 记录了字节数组的长度 11 ;
- content 属性保存着节点的值 “hello world” 。

图 7-10 展示了一个保存整数值的节点示例:
- 编码 11000000 表示节点保存的是一个 int16_t 类型的整数值;
- content 属性保存着节点的值 10086 。

连锁更新
前面说过, 每个节点的 previous_entry_length 属性都记录了前一个节点的长度:
- 如果前一节点的长度小于 254 字节, 那么 previous_entry_length 属性需要用 1 字节长的空间来保存这个长度值。
- 如果前一节点的长度大于等于 254 字节, 那么 previous_entry_length 属性需要用 5 字节长的空间来保存这个长度值。
现在, 考虑这样一种情况: 在一个压缩列表中, 有多个连续的、长度介于 250 字节到 253 字节之间的节点 e1 至 eN , 如图 7-11 所示。
因为 e1 至 eN 的所有节点的长度都小于 254 字节, 所以记录这些节点的长度只需要 1 字节长的 previous_entry_length 属性, 换句话说, e1 至 eN 的所有节点的 previous_entry_length 属性都是 1 字节长的。
这时, 如果我们将一个长度大于等于 254 字节的新节点 new 设置为压缩列表的表头节点, 那么 new 将成为 e1 的前置节点, 如图 7-12 所示。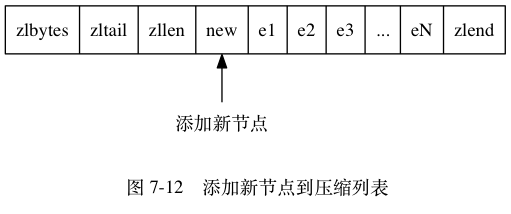
因为 e1 的 previous_entry_length 属性仅长 1 字节, 它没办法保存新节点 new 的长度, 所以程序将对压缩列表执行空间重分配操作, 并将 e1 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
现在, 麻烦的事情来了 —— e1 原本的长度介于 250 字节至 253 字节之间, 在为 previous_entry_length 属性新增四个字节的空间之后, e1 的长度就变成了介于 254 字节至 257 字节之间, 而这种长度使用 1 字节长的 previous_entry_length 属性是没办法保存的。
因此, 为了让 e2 的 previous_entry_length 属性可以记录下 e1 的长度, 程序需要再次对压缩列表执行空间重分配操作, 并将 e2 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
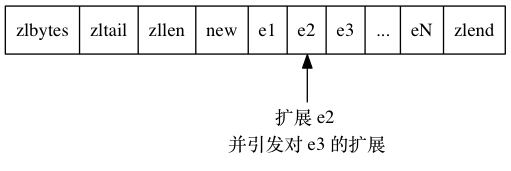
正如扩展 e1 引发了对 e2 的扩展一样, 扩展 e2 也会引发对 e3 的扩展, 而扩展 e3 又会引发对 e4 的扩展……为了让每个节点的 previous_entry_length 属性都符合压缩列表对节点的要求, 程序需要不断地对压缩列表执行空间重分配操作, 直到 eN 为止。
Redis 将这种在特殊情况下产生的连续多次空间扩展操作称之为“连锁更新”(cascade update), 图 7-13 展示了这一过程。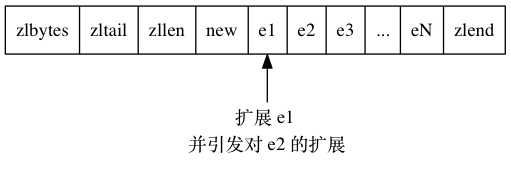


除了添加新节点可能会引发连锁更新之外, 删除节点也可能会引发连锁更新。
考虑图 7-14 所示的压缩列表, 如果 e1 至 eN 都是大小介于 250 字节至 253 字节的节点, big 节点的长度大于等于 254 字节(需要 5 字节的 previous_entry_length 来保存), 而 small 节点的长度小于 254 字节(只需要 1 字节的 previous_entry_length 来保存), 那么当我们将 small 节点从压缩列表中删除之后, 为了让 e1 的 previous_entry_length 属性可以记录 big 节点的长度, 程序将扩展 e1 的空间, 并由此引发之后的连锁更新。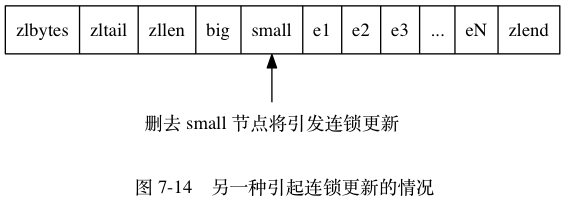
因为连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作, 而每次空间重分配的最坏复杂度为 O(N) , 所以连锁更新的最坏复杂度为 O(N^2) 。
要注意的是, 尽管连锁更新的复杂度较高, 但它真正造成性能问题的几率是很低的:
- 首先, 压缩列表里要恰好有多个连续的、长度介于 250 字节至 253 字节之间的节点, 连锁更新才有可能被引发, 在实际中, 这种情况并不多见;
- 其次, 即使出现连锁更新, 但只要被更新的节点数量不多, 就不会对性能造成任何影响: 比如说, 对三五个节点进行连锁更新是绝对不会影响性能的;
因为以上原因, ziplistPush 等命令的平均复杂度仅为 O(N) , 在实际中, 我们可以放心地使用这些函数, 而不必担心连锁更新会影响压缩列表的性能。
重点回顾
- 压缩列表是一种为节约内存而开发的顺序型数据结构。
- 压缩列表被用作列表键和哈希键的底层实现之一。
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
- 添加新节点到压缩列表, 或者从压缩列表中删除节点, 可能会引发连锁更新操作, 但这种操作出现的几率并不高。