几个星期前,我们开始了一个系列,目标是深入理解javascript和它怎么工作的:通过这些我们可以更容易的写出好代码和apps。
系列的第一篇主要是提供一个关于引擎,运行时和调用栈的概括。这篇文章将深入到Google V8 javascript 引擎。同时,还提供一些快速的意见令你能够写出好的javascript代码。
概览
一个javascript引擎是一个解释器也是个程序,它执行javascript代码。它可以被实现为一个标准解释器,也可以是一个即时(just-in-time)的编译器(以不同形式编译javascript成字节码)
下面是一个流行的javascript引擎的列表:
- V8 — 谷歌开源的, 用 C++写的。
- Rhino — 由Mozilla基金会管理,开源的, 完全用java写的。
- SpiderMonkey — 第一个javascript引擎 Netscape Navigator开发,现在Firefox维护。
- JavaScriptCore — 开源,由Apple开发 ,Safari浏览器的引擎。
- KJS — KDE的引擎,由 Harri Porten开发,是Konqueror桌面系统的浏览器引擎。
- Chakra (JScript9) — IE的
- Chakra (JavaScript) — 微软Edge
- Nashorn - OpenJDK的开源一部分, 由Oracle Java 语言和工具组开发
- JerryScript — 一个轻量级引擎.
为什么要创造一个V8引擎?
V8引擎由Google创建并开源,c++编写。用于Google的Chrome浏览器。不像其他引擎,V8还是流行的Node.js的运行时引擎。
V8是第一个为了性能提升的浏览器引擎。为了达到更好的性能,相比于使用解释器,V8更倾向于使用编译器编译javascript代码成更高效的机器码。它像其他现代化javascript引擎如SpiderMonkey或者Rhino (Mozilla)一样,使用JIT(Just-In-Time)编译器在执行阶段编译代码,唯一不同的是,V8不会生成字节码或任意中间代码。
V8曾经有两个编译器
在5.9版本发布(今年早些时候)之前,V8曾经有两个编译器:
- full-codegen — 一个简单快速的编译器,用来生成简单,相对慢的机器码。
- Crankshaft - 一个更复杂(Just-In-Time) 优化的编译,用来生成更优的机器码。
V8引擎内部也用了一些线程:
- 正如你想的,主线程就是拿到代码,编译代码和执行代码。
- 还有些线程用来编译和优化代码,协助主线程,让主线程继续执行代码。
- 一个剖析器线程用来汇报哪些方法需要Crankshaft编译器优化。
- 其他一些线程用来做垃圾回收
当开始执行javascript代码,V8运用full-codegen来直接翻译解析过的javascript代码为机器码,这个过程没有任何中间转换,所以执行机器码非常快.由于没有用到任何中间的字节码,所以就没有需要解释器的必要了。
当你的代码运行一段时间后,剖析器线程就能收集到足够的数据来确定哪些方法应该被优化。
接下来,Crankshaft 优化编译器开始运行在其他线程。它翻译javascript抽象语法树到一个高级别的静态单赋值(SSA) 形态,又叫Hydrogen(氢?)。然后优化这个Hydrogen图。大部分的优化都在这个层次上完成。
内联(inlining)
首个优化方法就是内联,它会提前尽可能的内联更多的代码。内联是一个替换代码的一个过程,用方法体替换到调用的地方(其实就是方法展开)。这样一步简单的优化可以令接下来的优化更有意义。
隐藏类(Hidden class)
javascript是一种基于原型的语言:没有类和对象是通过克隆进程创建的(机翻😁)。javascript也是一种动态语言,他能够随意的添加和删除一个对象的属性,即使这个对象已经实例化了。
大部分javascript解释器使用类字典的结构(基于哈希函数)来存储对象属性值在内存的位置。相比非动态语言如java和c#,这种结构使得取值是种计算昂贵的操作。对java来说,在编译之前就已经确定对象的属性,运行时也不能随意添加和删除属性的(当然,c#支持动态类型,那就在其他话题里了)。所以,属性的值(或者属性的指针)可以存储在一个连续的缓存里面,属性之间的位移更是固定的,而且位移的长度可以容易的基于属性类型来确定。这些对于javascript来说是不可能的,因为javascript的类型可以在运行时改变。
由于这种字典的取地址方式是不高效的,所以V8用了一个不同的方法来取代:隐藏类(Hidden class)。隐藏类的运作方式跟java的固定对象布局类似,除了它们是在运行时创建的。下面举个栗子:1
2
3
4
5function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
一旦new Point(1, 2)被调用,V8将创建一个C0的隐藏类。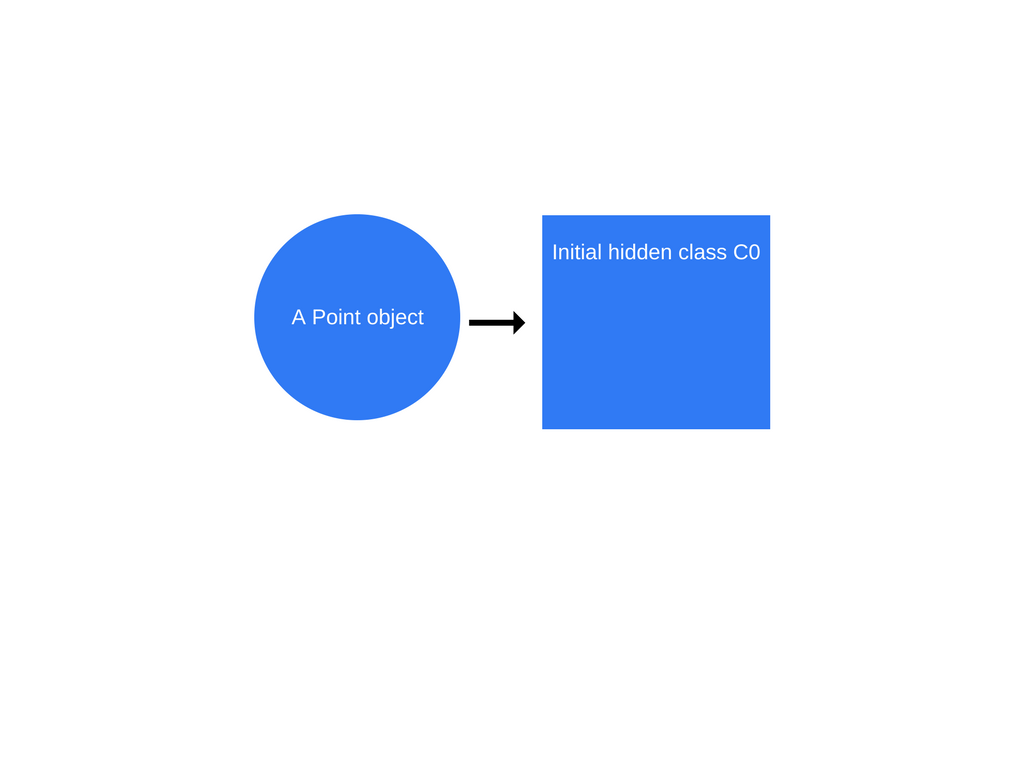
由于Point没有属性定义,所以C0是空的。
一旦this.x = x(在Point函数)被执行,V8将创建一个基于C0的隐藏类C1。C1描述了x的内存的位置(相对于对象指针),在这个情况下,x的位置存在位移0上,这代表了point对象是一个连续的内存,它的第一个位移对应的是属性x。同时V8也用“类转换”更新了C0,表明了如果一个属性x加到point对象,隐藏类就应该要从C0转换到C1。所以现在point对象的隐藏类为C1。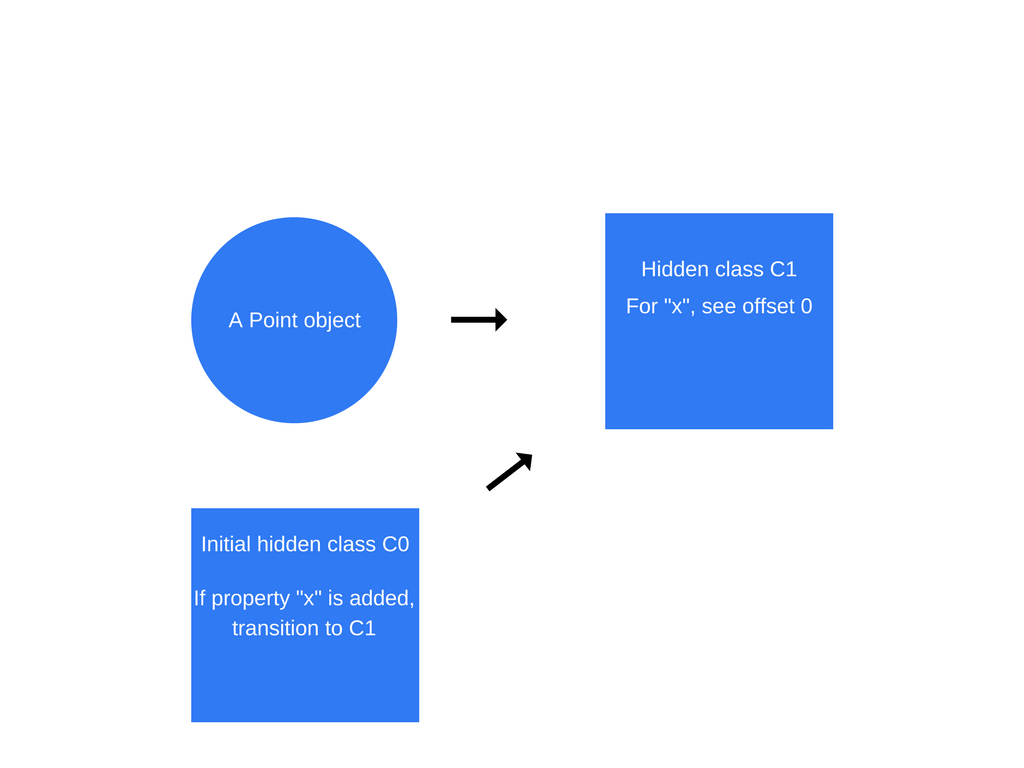
每一次一个新的属性加到一个对象,一条转换的路径更新到旧的隐藏类并指向新的隐藏类。隐藏类转换是很重要的,因为同样方式创建的对象都共享同一个隐藏类。如果两个对象共享一个隐藏类,同时相同的属性加到这个两个对象的话,那么转换将保证这两个对象还是共享同一个新的隐藏类,而且共享同一个隐藏类有益于优化代码。
当this.y = y被执行,一个新的隐藏类C1被创建,同时一个类转换加到C1上面,表明了如果一个属性y加到一个point对象(已经有x属性的),就要把隐藏类转换成C2。现在point对象的隐藏类就是C2了。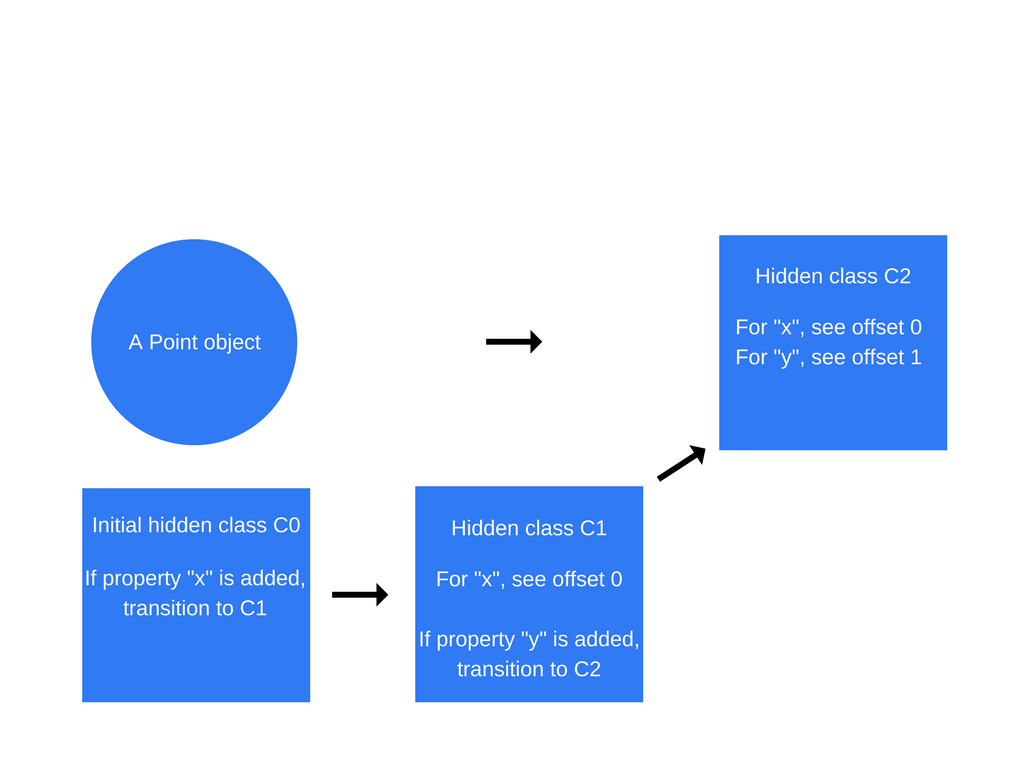
隐藏类的转换依赖于属性的加入顺序。看一下下面的代码:1
2
3
4
5
6
7
8
9
10function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
现在你肯定会认为p1和p2都是共享同一个隐藏类和转换路径,其实不然。对于p1,第一个属性是a再到b,而p2的话是先b在到a,所以p1和p2是分别两个不同的隐藏类和不同的两条转换路径。所以,对于动态属性最好是用相同的顺序加入到对象里面,这样有利于隐藏类的重用。
内联缓存(Inline caching)
V8利用内联缓存技术来优化动态类型语言。内联缓存依赖于观察哪些方法在哪些相同的对象类型被重复调用。更深的介绍可以看这里
我们用更通用的概念来说说内联缓存(如果你没时间去看上面的介绍的链接的话。)
所以,内联缓存是怎么工作的呢?V8维护一个对象类型的缓存,当一个对象做为参数传递到一个函数调用中,那V8会缓存这个对象,并假设这个对象会在未来会再一次作为参数传递到一个函数调用中。如果V8的这个假设是正确的话,在下次传递对象到一个方法调用的时候,就会绕过查找类型对象的属性的过程,直接使用之前查找隐藏类所储存的信息。
所以隐藏类和内联缓存是怎么样关联起来的呢?无论一个指定对象方法什么时候被执行,V8引擎都会去查找那个对象的隐藏类去决定指定属性的访问位移。在两次成功调用相同隐藏类的相同方法后,V8就会忽略隐藏类的查找并简单的用属性位移和这个对象指针相加来确定地址。对于未来的那个方法的调用,V8都假设这个对象的隐藏类都没有改变,直接使用之前查找后对象内存的位移来访问属性,这样大大增加执行速度。
相同类型的对象共享相同隐藏类是很重要的,原因是内存缓存。如果你创建两个相同类型的对象,但它们的隐藏类不同(前面例子有提到),V8将没办法用到内联缓存,因为尽管类型相同,但是它们对应的隐藏类分配的属性位移是不同的。
这两个对象基本上是一样的,但是a和b属性是用不同的顺序创建的。
编译机器码
一旦Hydrogen图被优化,Crankshaft降低它为一个低级别的表述,称为Lithium。大多数Lithium实现是架构指定的。注册器分配发生在这个级别。
最后,Lithium被编译为机器码。有一些编译发生在OSR:栈中替换。在我们编译和优化一个明显长时间运行的方法时,我们有可能已经运行了这个方法了。V8不会忘了这个方法重新运行一个优化的版本的方法,而是转换所有的上下文(栈,注册器),这样就可以在执行中切换到优化版本。这是一个复杂的任务,记得在其他优化里,V8已经一开始就内联代码了。V8不是唯一有这能力的引擎。
这里有个保障是,一旦引擎的假设不成立的话,会把优化过的代码回滚回之前未优化的代码。这个保障称之为去优化(deoptimization)
垃圾回收
对于垃圾回收,V8使用传统的分代标记清理的方式来清除旧的对象。标记的阶段一般都会停止javascript的执行。为了控制GC的成本和令执行更加稳定,V8用了递增标记来取代全堆标记。递增标记只是在部分堆中递增标记可能的对象,之后回到正常的代码执行。到下次执行GC的时候,会从上次GC标记的堆中开始。这样的话,停止时间很少。之前提及过,清理过程是在不同的线程执行的。
Ignition和TurboFan
V8的5.9版本在2017年初发布,一个新的执行管道被引入。这个新的管道使得V8在现实的javascript应用程序中达到更高的性能和更少内存使用。
新的执行管道由V8解释器Ignition和V8最新优化编译器TurboFan 组成。
你可以在这里查阅来自V8团队的博客文章.
自从5.9版本的V8发布,full-codegen和Crankshaft(这两个技术从2010就开始服务V8了)不再被V8用来执行javascript,当V8团队要跟上新的javascript语言特性的步伐和这些特性更需要优化的支持。
这就意味着V8总体来讲将是一个更简单和更容易维护的架构。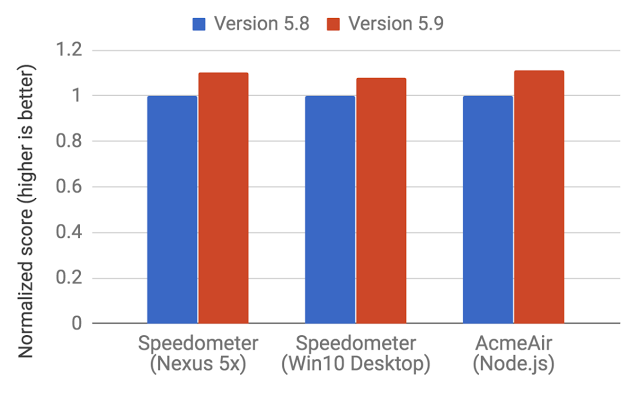
在网页和Node.js的性能改进
这些改进只是个开始。新的Ignition和TurboFan为更长远的优化铺平了道路,并在这几年提升javascript的性能和缩小Node.js和Chrome的差距。
怎么写出最好的javascript代码
最后,这里有些建议帮助你们写出更优更好的javascript。我想,当你看到这里,你心里已经有所感悟了,但是,我还是总结下吧:
- 对象属性的顺序:初始化对象属性最好要按相同顺序,这样,他们的隐藏类和后续的优化代码能够共享。
- 动态属性:加一个动态属性会令一个对象的隐藏类改变,和拖慢任何一个方法,因为这个方法已经针对前一个隐藏类优化的了。所以,尽可能分配在构造函数里面分配所有的对象属性。
- 方法:重复执行相同的方法比一次执行许多不同的方法快(因为内联缓存)
- 数组:避免稀疏数组,因为它们的key不是递增的。稀疏数组并不是每个索引都有元素,所以它更像个哈希表。还有访问这样的数组是昂贵的。还有就是不要一次分配个大数组,最好按需分配。最后,不要在数组中删除元素,这样就令key稀疏了。
- 标签值:V8用32位来代表对象和数字。它用一位来区分对象(flag=1)和整形(flag=0),这个整形也叫SMI(SMall Integer),因为它只有31位。这样的话,如果一个数字值大于31位,V8将会将它转化为一个double并使用一个对象把它装箱。尽可能使用31位的有符号数字,这样能够避免昂贵的装箱操作。