引言
我们很多人是开发者,每天写大量的代码,有时也不是糟糕的代码。每个人都能很轻松写下这样的代码:1
2
3
4
5
6
7
8
int main() {
int x = 10;
int y = 100;
printf("x + y = %d", x + y);
return 0;
}
大家都能理解上面这段 C 语言代码完成的功能,但是…这段代码底层是如何工作的呢?我想我们中间不是所有人都能回答这个问题,我也不能。我认为我可以用高级编程语言写代码,例如 Haskell、Erlang、Go 等等,但是我完全不知道在编译之后它在底层是如何工作的。所以,我决定往下再深入一步,到汇编这个层次,并且记录下我的学习汇编之路。希望这是有趣的过程,而不是仅仅对我一个人。大约五、六年前我已经使用过汇编来写简单的程序,那时我还在上大学,用的是 Turbo 汇编和 DOS 操作系统。现在我使用 Linux-x86_64 操作系统,是的,64 位 Linux 和 16 位 DOS 肯定有很大的不同。那我们就开始吧。
准备阶段
在开始之前,我们需要准备一些我接下来要提到的东西。我使用的是 Ubuntu(Ubuntu 14.04.1 LTS 64 位) 系统,因此我的文章都是基于该操作系统和体系结构的。不同的 CPU 支持不同的指令集,我使用的是 Intel Core i7 870 处理器,所有代码都在这上面运行。另外我将用 nasm 汇编,你可以用下面命令来安装:1
sudo apt-get install nasm
这就是目前我们需要准备的所有东西,其它工作在接下来的文章中会提到。
x64 语法
这里我就不全面介绍汇编的语法了,我们仅提一下这篇文章中用到的语法。通常 NASM 程序会被划分为不同的段(section),这篇文章中我们会涉及到两个段:
- 数据段(data section)
- 代码段(text section)
数据段用来定义常量(constant),常量是在运行时不会改变的数据。你可以定义数字或其他常量等等,声明一个数据段的语法如下:1
section .data
代码段是存放代码(code)的,该段必须以 global _start 开始,告诉内核这里是程序开始执行的地方。1
2
3section .text
global _start
_start:
注释是以 ; 开始。每个 NASM 代码行包含下面四个字段的组合:1
[label:] instruction [operands] [; comment]
中括号括起来的字段表示是可选的。基本 NASM 指令由两部分组成,第一部分是需要执行指令的名字,第二部分是该指令的操作数。例如:1
MOV COUNT, 48 ;将数值 48 存放到 COUNT 变量中
Hello world
让我们用 NASM 汇编来写第一个程序吧,当然是传统的打印 “Hello world” 的程序。这是代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14section .data
msg db "hello, world!"
section .text
global _start
_start:
mov rax, 1
mov rdi, 1
mov rsi, msg
mov rdx, 13
syscall
mov rax, 60
mov rdi, 0
syscall
是的,看起来不像 printf(“Hello world”),我们试着去理解它是什么、怎么工作的。先看 1-2 行,我们定义了一个数据段,并且有一个 msg 常量,值为 Hello world,那么我们就可以在代码中使用这个常量了。下一步是定义了一个代码段,以及程序的入口,代码从第 7 行开始执行。现在到了程序最有意思的部分了。我们已经了解了 mov 指令的功能,它带有两个操作数,将第二个操作数的值放到第一个操作数中。但是,rax、rdi 等等这些是什么呢?我们找到维基百科的解释:
中央处理单元(CPU)是计算机中的硬件,它读取计算机程序中的指令,完成系统中基本的算术、逻辑、输入/输出操作。
好了,CPU 完成一些操作,例如算术操作等,但是它从哪获得操作的数据呢?第一个答案是内存。然而从内存中读取和存入数据的速度远远低于处理器的速度,它涉及到复杂的通过控制总线来发送数据请求的过程。因此,CPU 有其内部的存储位置,称为寄存器(register)。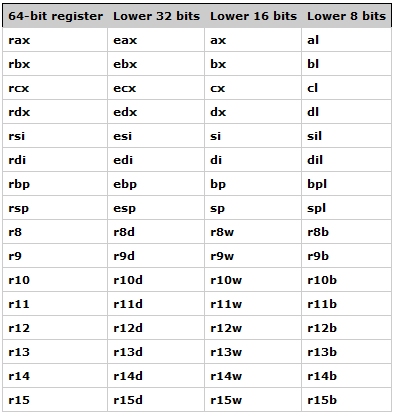
那么我们写 mov rax, 1,意思是将 1 放到 rax 寄存器中。现在我们知道什么是 rax、rdi、rbx 等等了吧,但是还需要知道什么时候使用 rax,什么时候使用 rsi 等等。
- rax —— 临时寄存器,当我们调用系统调用时,rax 保存系统调用号
- rdx —— 用来向函数传递第三个参数
- rdi —— 用来向函数传递第一个参数
- rsi —— 用来向函数传递第二个参数的指针
换句话说,我们就是调用了 sys_write 系统调用,该函数原型是:1
ssize_t sys_write(unsigned int fd, const char *buf, size_t count)
它有三个参数:
- fd —— 文件描述符,0、1、2 分别代表标准输入、标准输出和标准错误
- buf —— 字符数组的指针,用来保存从 fd 指向的文件中获取的内容
- count —— 表示要从文件中读入到字符数组的字节数
我们知道 sys_write 系统调用带有三个参数,它在系统调用表中有一个系统调用号。我们再看看程序的实现,将 1 放到 rax 寄存器中,它意思是我们使用 sys_write 系统调用;下一行将 1 存到 rdi 寄存器,它是 sys_write 的第一个参数,1 代表标准输出;然后我们将 msg 的指针存到 rsi 寄存器中,这是 sys_write 的第二个参数 buf;接着我们传递 sys_write 最后一个参数(字符串的长度)到 rdx 寄存器中。现在,我们有了 sys_write 的所有参数,就可以在 11 行使用 syscall 来调用它了。好了,我们打印出 “Hello world” 字符串,现在需要从程序中正确退出。我们传递 60 到 rax 寄存器,60 是 exit 的系统调用号;以及将 0 传递给 rdi 寄存器,这是错误码,0 表示我们的程序正确地退出。这就是 “Hello world” 的所有分析,相当简单吧:)现在我们编译程序,假设我们的程序放在 hello.asm 文件中,那么我们需要运行下面的命令来执行:1
2nasm -f elf64 -o hello.o hello.asm
ld -o hello hello.o
编译链接完成之后,我们得到可执行文件 hello,可以使用 ./hello 来运行,可以在终端看到输出 “Hello world”。
总结
本文用一个简单不能再简单的程序开始第一部分,接下来我们会看到一些算术运算。如果你有任何问题或者建议可以给我评论。
参考 http://blog.jobbole.com/84776/ 此链接翻译了 https://github.com/0xAX/asm 的第一章
原作者源码 https://github.com/0xAX/asm
已加入我的repo https://github.com/ejunjsh/asm-code